Применение и оптимизация работы LLM. RAG, борьба с галлюцинациями

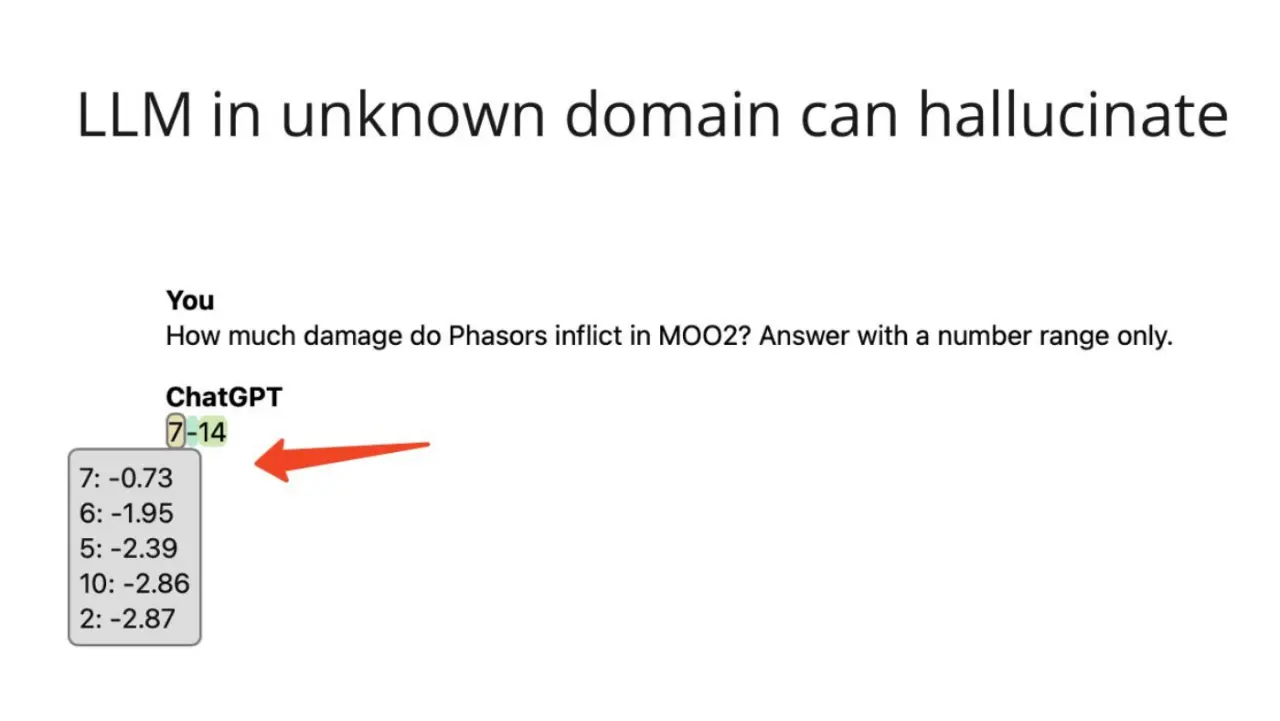
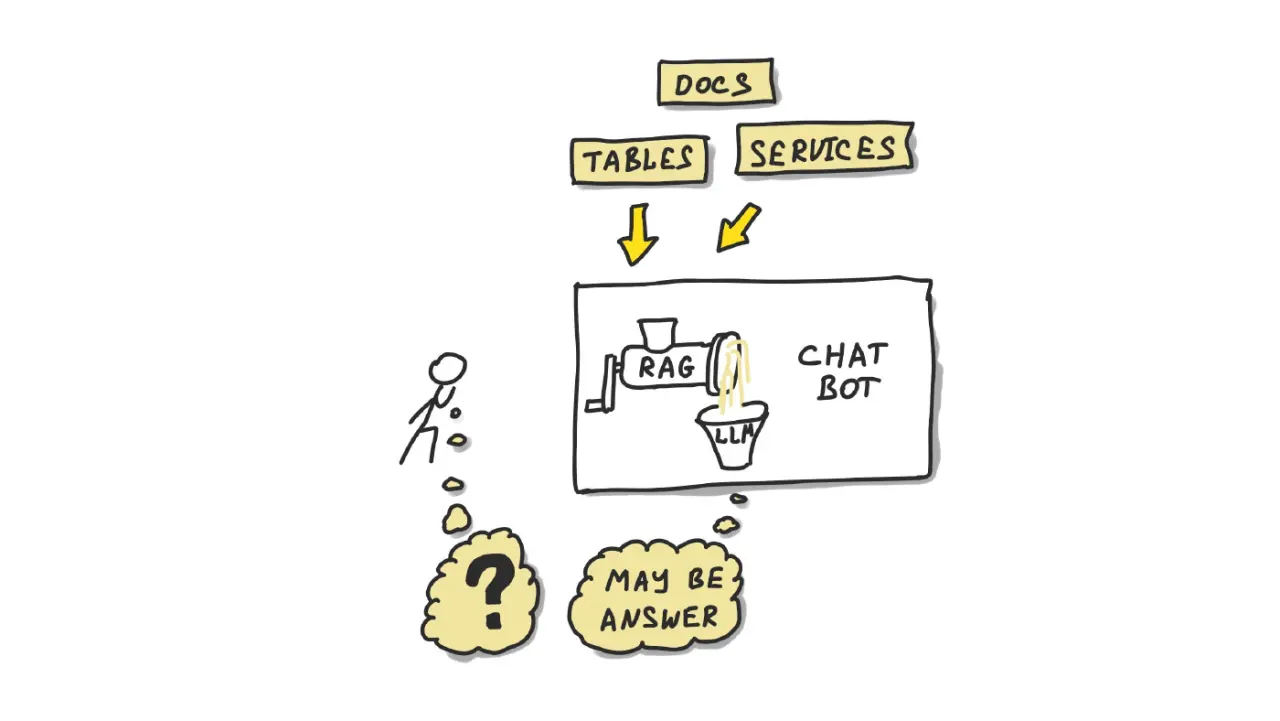
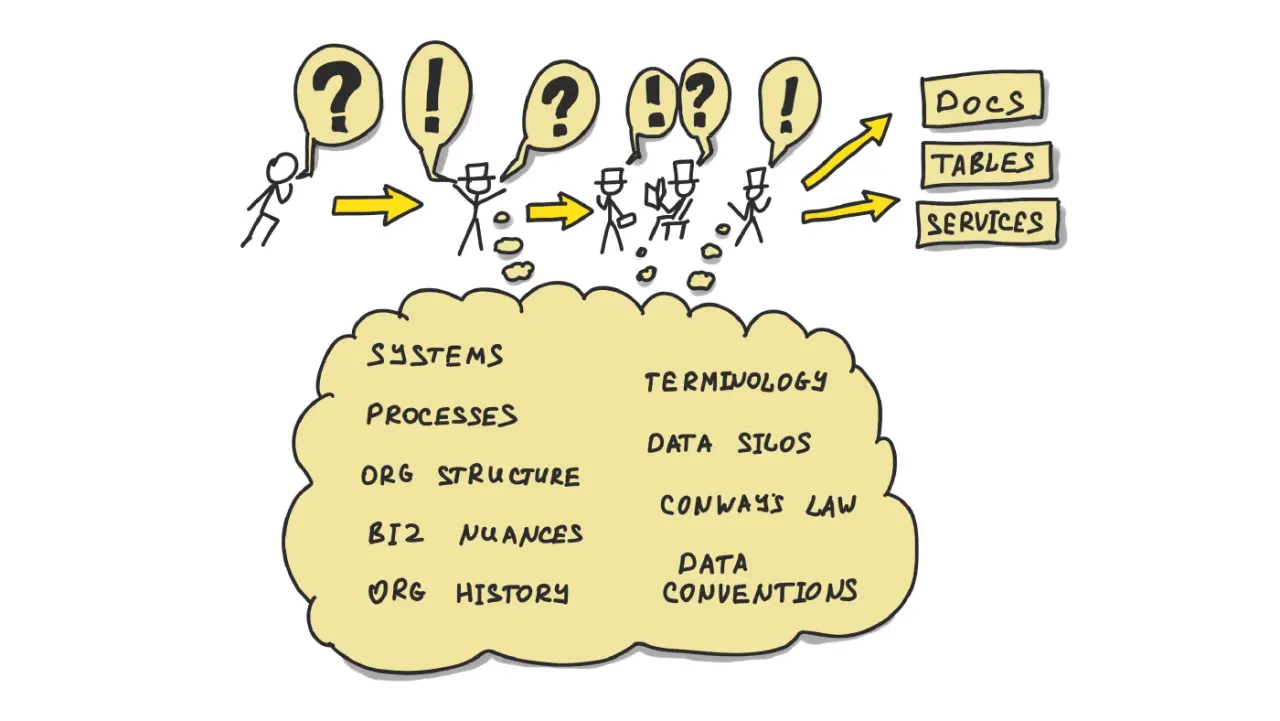
Большие языковые модели легко показать в демо, но в реальном продукте они быстро упираются в две проблемы: модель выдумывает факты и ведёт себя менее стабильно, чем хотелось бы. RAG (retrieval-augmented generation) и продуманная оптимизация — то, что отделяет рабочий продукт от красивой демки.
Азамат Галимжанов — CEO azamat.ai, разработчик с 20-летним опытом, прошедший через два успешных экзита, — разбирает, как применять и оптимизировать LLM на практике: как строить RAG и как бороться с галлюцинациями модели.
Видео
Часть 1
Часть 2
Презентация
 1 / 34
1 / 34

















Текст презентации
Слайд 1: Работа с LLM
Работа с LLM RAG, борьба с галлюцинациями
Слайд 2: Азамат Галимжанов
Азамат Галимжанов - Профессиональный разработчик с 2007 - Изучаю AI \ ML с 2011 - Стартапы гдематериал, biometric.vision - Занимаюсь generative AI с 2022 @aza_ai_expert
Слайд 3: Что такое LLM?
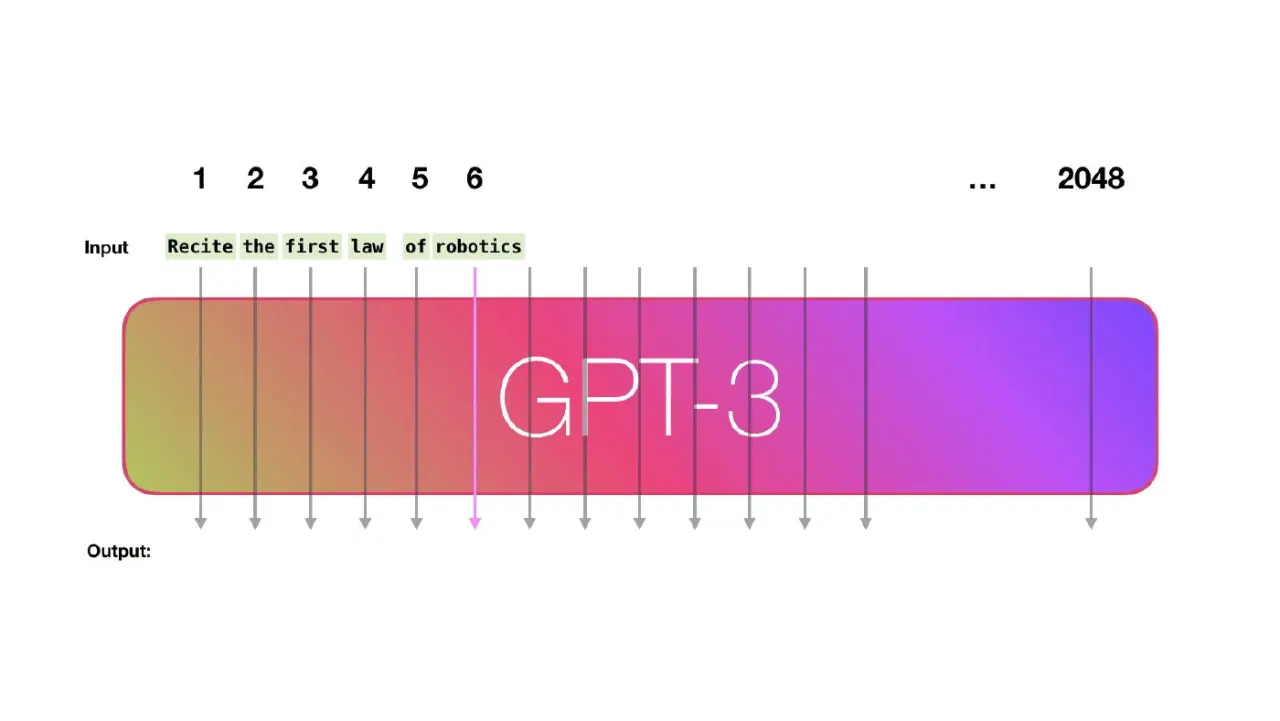
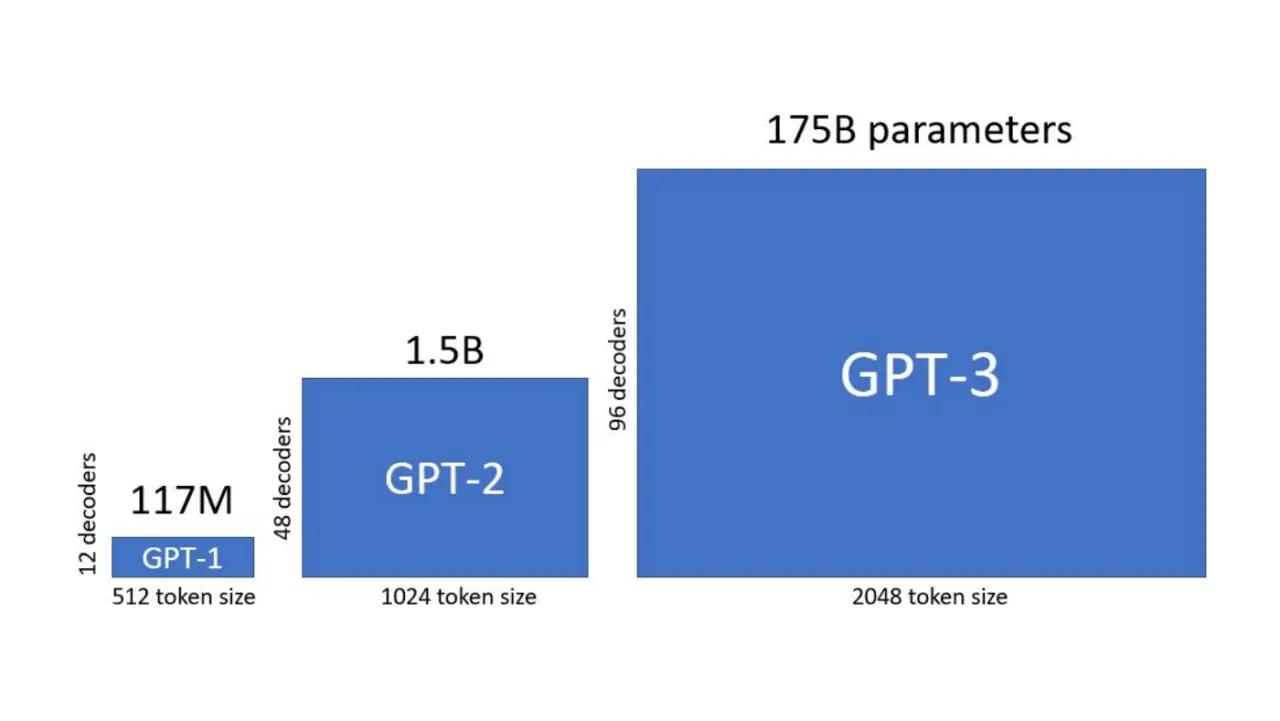
Что такое LLM?
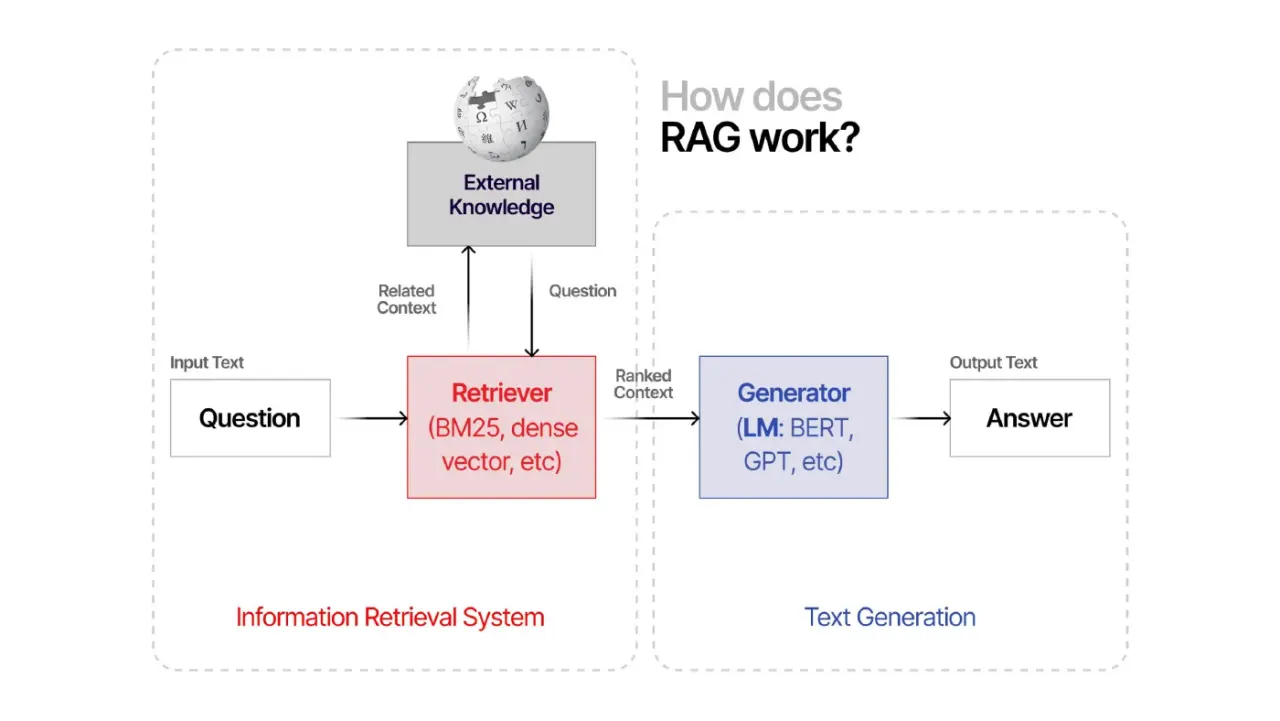
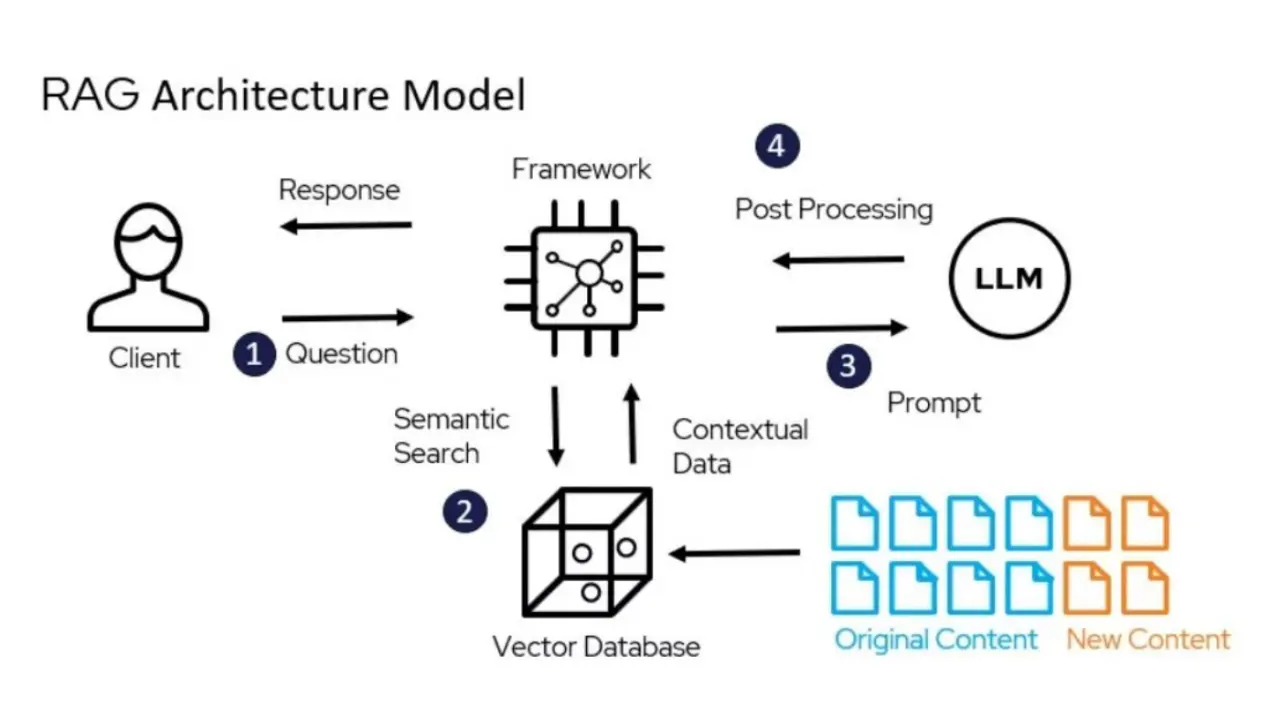
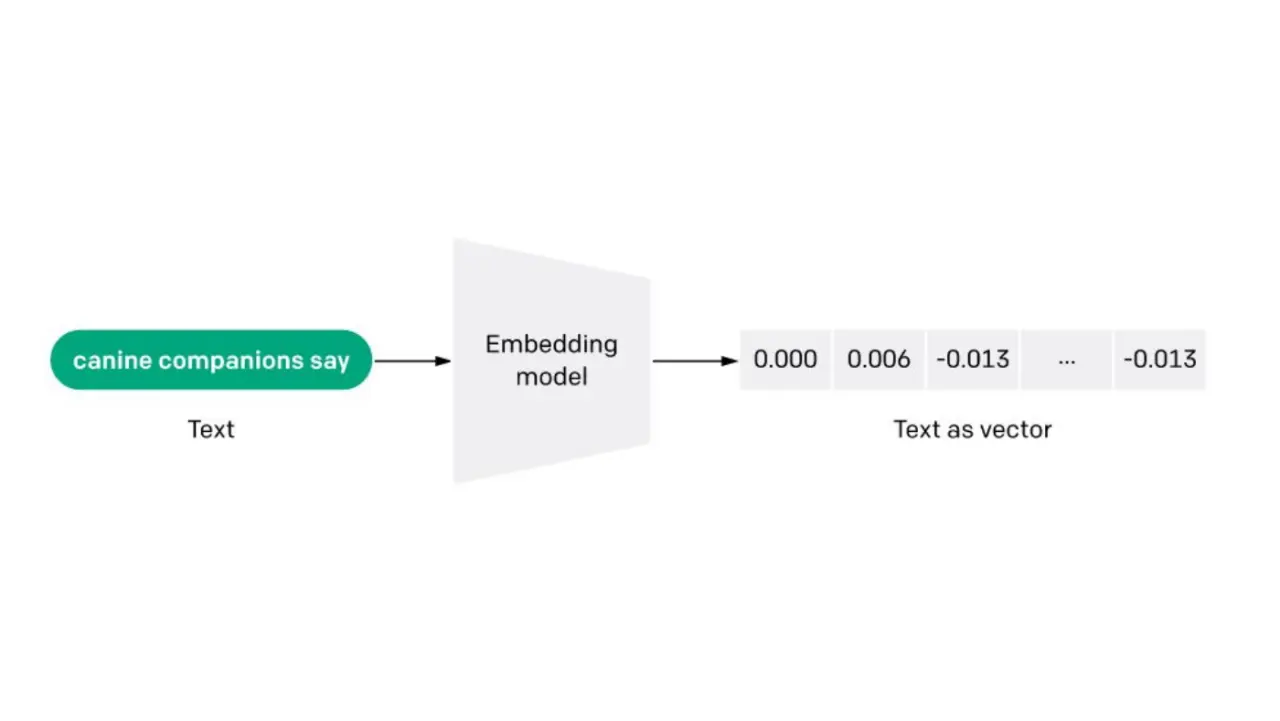
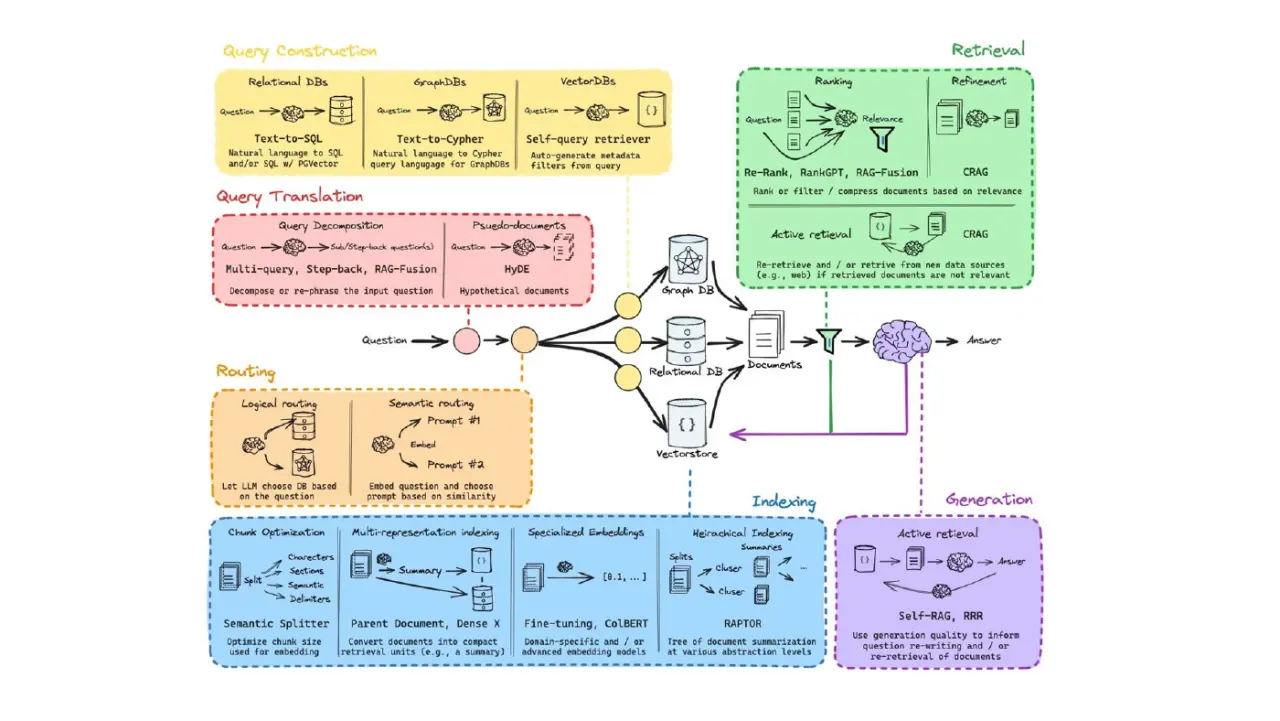
Слайд 19: Что такое RAG?
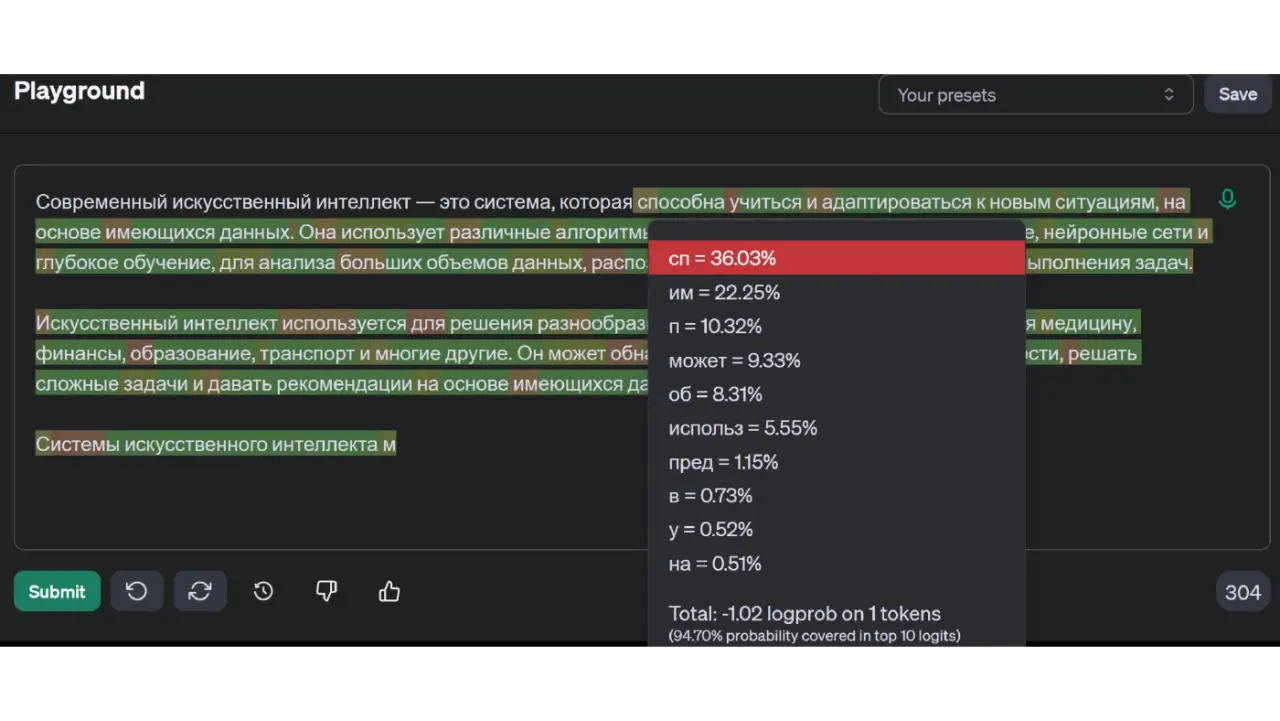
Что такое RAG?
Другие доклады митапа
- РС
- Д
- ДТCelery — Best Practices Даурен Талгатулы
