От проблем к решениям в дата-приложениях. История одного источника
Интеграция с внешним источником данных редко идёт гладко — этот доклад про то, что ломается по пути и что с этим делать.
Роман Савоськин — Data Engineer Lead в Halyk Bank — делится историей одной интеграции в области закупок: какие проблемы возникли, какие решения перебирали и на каких остановились.
В докладе: — подход «от проблемы к решению» на реальном источнике данных — производительность в контексте Python — Kafka, хранилище и прокси — схемы валидации, сериализации и десериализации — построение верхнеуровневого API: стандартизация ответов и аккуратная обработка ошибок (без «голых» 500-к) — паттерн «репозиторий» для работы с БД без ORM и миграции
Видео
Презентация
 1 / 49
1 / 49































Текст презентации
Слайд 1: Roman Savoskin. Data Engineer Lead @ Halyk Bank
Roman Savoskin. Data Engineer Lead @ Halyk Bank От проблем к решениям в приложениях данных История одного источника
Слайд 2: Поделиться конкретными решениями типовых проблем
Поделиться конкретными решениями типовых проблем Проблема Это нечеткое описание цели или недостатков системы которые требуется исправить Решение Это способ, позволяющий разрешить противоречия, выявленные по итогам анализа проблемы
Слайд 3: За основу - область закупок
За основу - область закупок На комиссии: ~20 млрд Заказчик Хочу дорогу, заплачу не более 1 млрд Банк Поставщик Дай деньги и тебя никто не кинет Все сделаю, и даже дешевле чем заказчик хотел
Слайд 4: Строим интеграционные API
Строим интеграционные API
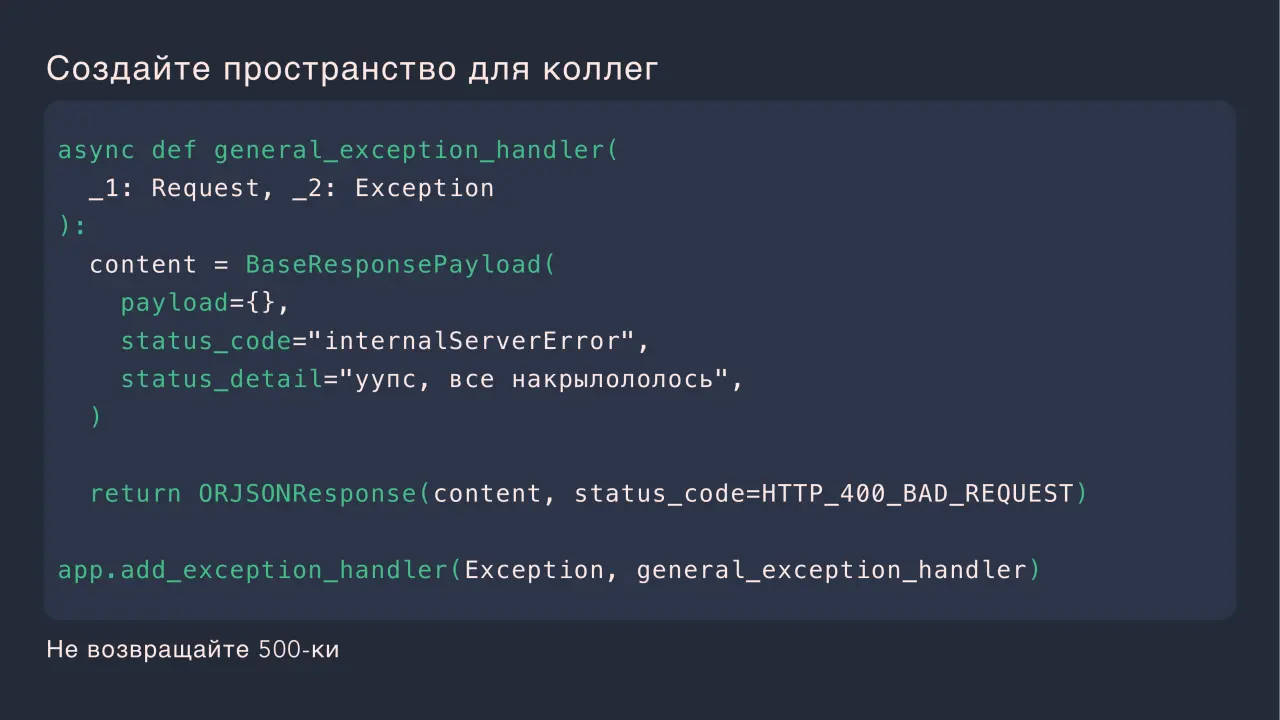
Слайд 5: Создайте пространство для коллег
Создайте пространство для коллег Не возвращайте 500-ки async def general_exception_handler( _1: Request, _2: Exception content = BaseResponsePayload( payload={}, status_code="internalServerError", status_detail="уупс, все накрылололось", return ORJSONResponse(content, status_code=HTTP_400_BAD_REQUEST) app.add_exception_handler(Exception, general_exception_handler)
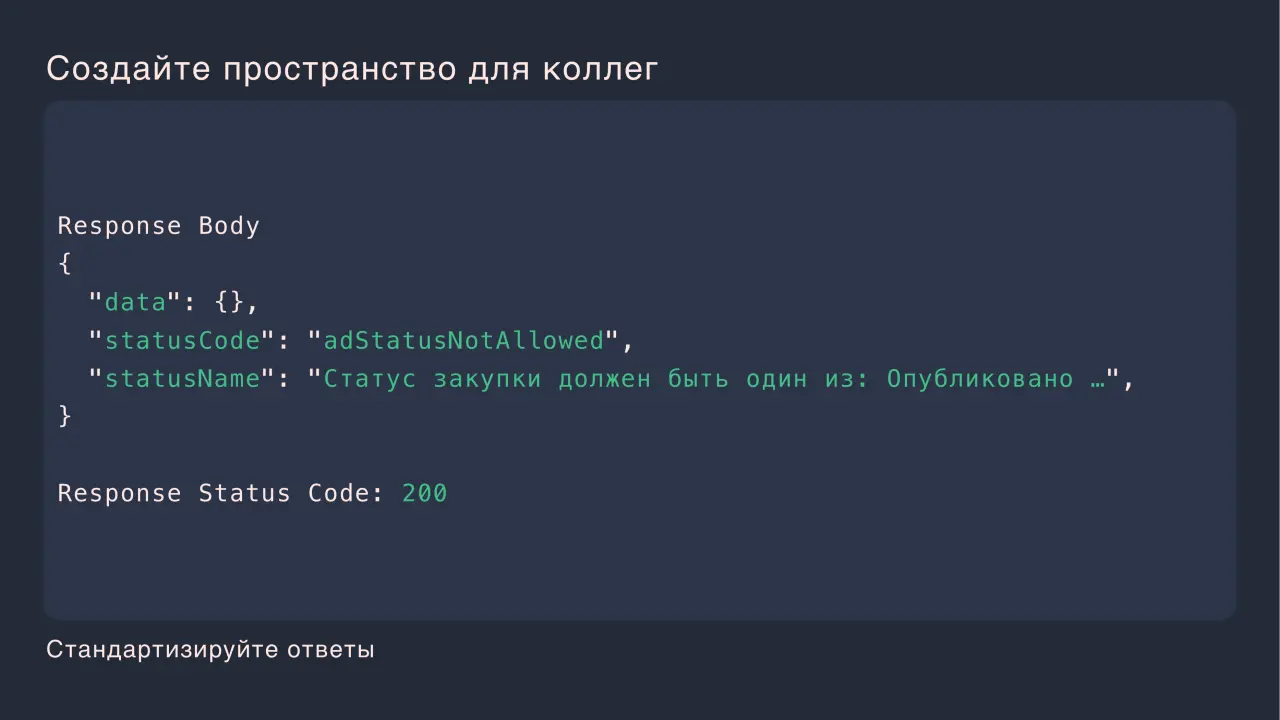
Слайд 6: Создайте пространство для коллег
Создайте пространство для коллег Стандартизируйте ответы Response Body "data": {}, "statusCode": "adStatusNotAllowed", "statusName": "Статус закупки должен быть один из: Опубликовано …", Response Status Code: 200
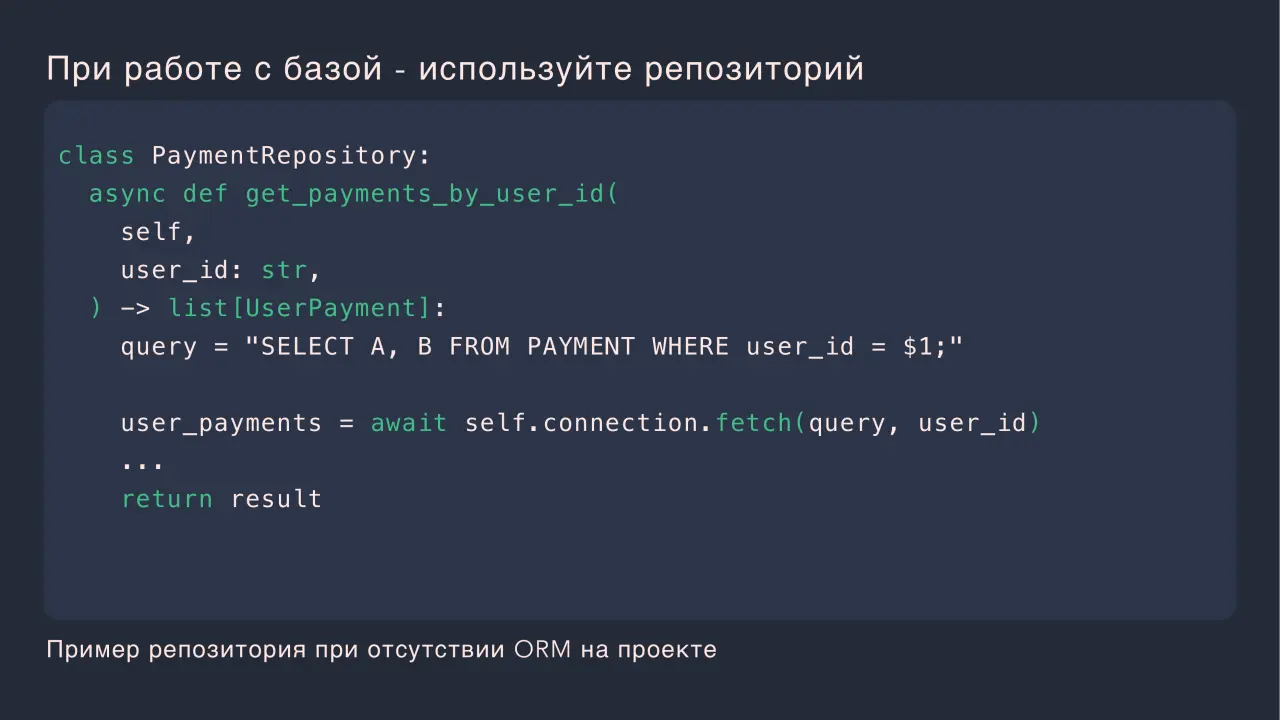
Слайд 7: При работе с базой - используйте репозиторий
При работе с базой - используйте репозиторий class PaymentRepository: async def get_payments_by_user_id( self, user_id: str, ) -> list[UserPayment]: query = "SELECT A, B FROM PAYMENT WHERE user_id = $1;" user_payments = await self.connection.fetch(query, user_id) return result Пример репозитория при отсутствии ORM на проекте
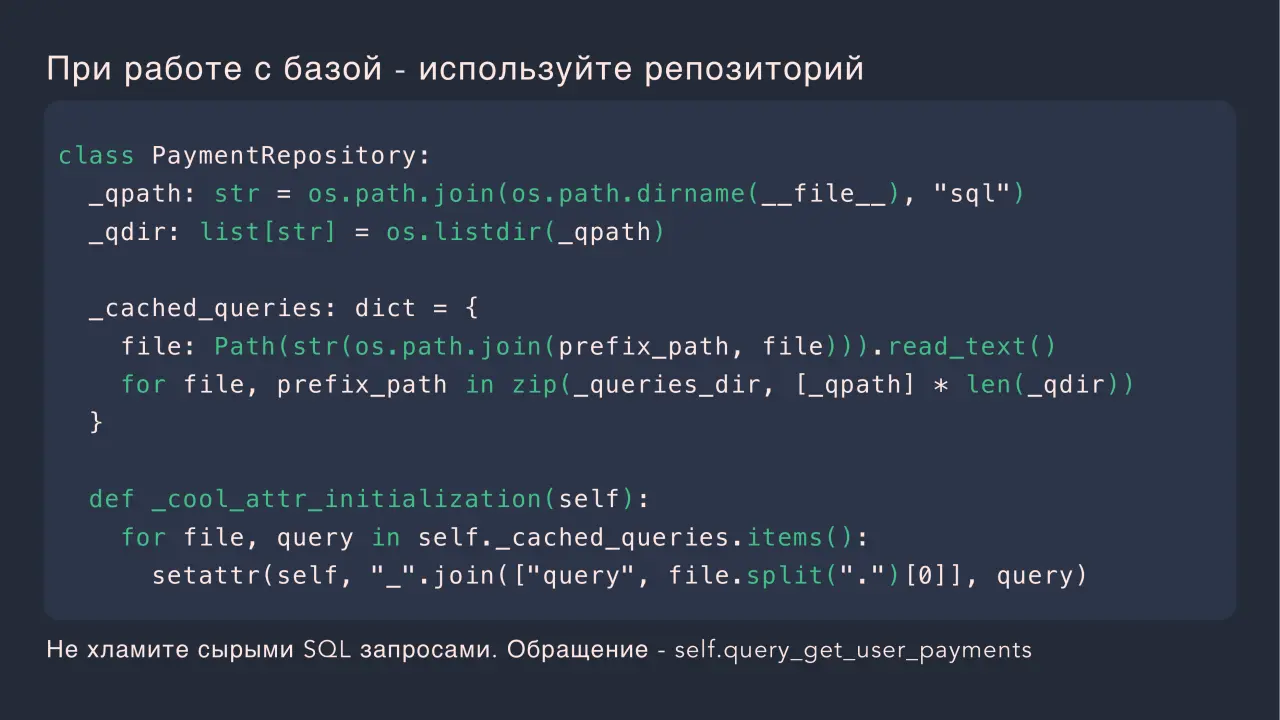
Слайд 8: При работе с базой - используйте репозиторий
При работе с базой - используйте репозиторий class PaymentRepository: _qpath: str = os.path.join(os.path.dirname(__file__), "sql") _qdir: list[str] = os.listdir(_qpath) _cached_queries: dict = { file: Path(str(os.path.join(prefix_path, file))).read_text() for file, prefix_path in zip(_queries_dir, [_qpath] * len(_qdir)) def _cool_attr_initialization(self): for file, query in self._cached_queries.items(): setattr(self, "_".join(["query", file.split(".")[0]], query) Не хламите сырыми SQL запросами. Обращение - self.query_get_user_payments
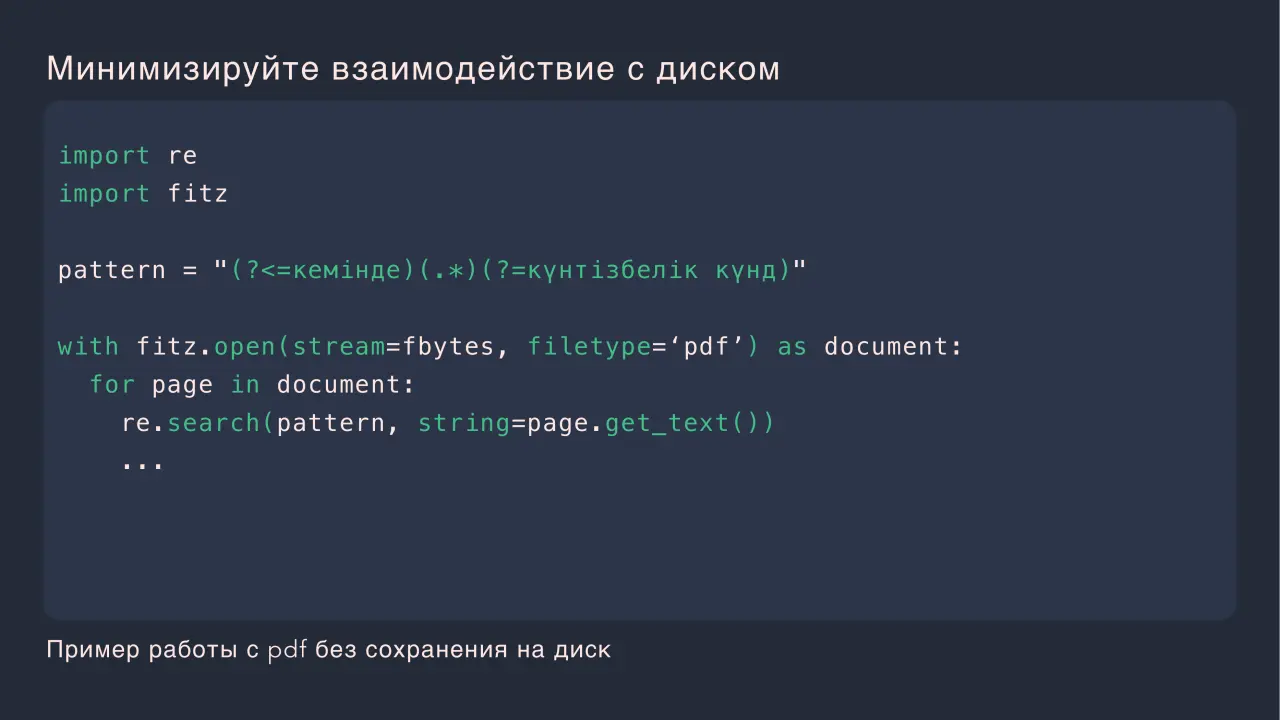
Слайд 9: Минимизируйте взаимодействие с диском
Минимизируйте взаимодействие с диском import re import fitz pattern = "(?<=кемінде)(.*)(?=күнтізбелік күнд)" with fitz.open(stream=fbytes, filetype=‘pdf’) as document: for page in document: re.search(pattern, string=page.get_text()) Пример работы с pdf без сохранения на диск
Слайд 10: Часть логики - переносите на уровень Базы Данных
Часть логики - переносите на уровень Базы Данных try: repo.validate_and_create_token(…) except asyncpg.exceptions.RaiseError as e: error_code = str(e) if error_code == "UserNotFound": raise UserNotFound Базовый сценарий обработки ошибки полученный из БД
Слайд 11: О чем еще помнить при выстраивании API
О чем еще помнить при выстраивании API - Ваш API должен работать при недоступности внешних систем - Эндпоинты не должны влиять друг на друга - При большой CPU нагрузке на определенные эндпоинты - выносим их
Слайд 12: Настраиваем загрузку данных для аналитики
Настраиваем загрузку данных для аналитики
Слайд 13: Описание источника - вводные
Описание источника - вводные - Предоставили graphql API. За раз - 200 записей
Слайд 14: Данные нужны на T-1
- Данные нужны на T-1 - Данные должны загружаться до начала рабочего дня - Хочу видеть историю изменений объекта Описание источника - цель
Слайд 15: Нет прямого способа узнать какой объект изменился
- Нет прямого способа узнать какой объект изменился - Данные могут измениться задним числом ( в том числе и удалиться ) - Данные в graphql становятся доступны с задержкой Описание источника - НО
Слайд 16: Возможные варианты решения
Возможные варианты решения Очевидное Каждый день грузить всю историчность. Метка LOAD_DATE позволит версионировать Минусы - SSD/HDD - Ошибки в загрузках >1 дня Темпоральное Логическое Каждый день загружаем только новые данные. Заводим метки date_begin и date_end. Минусы - Сложность Каждый день загружаем только новые данные. На старые и обновленные вешаем метку is_deleted Минусы - Долго ЛИБО сложно
Слайд 17: Возможные варианты решения
Возможные варианты решения Очевидное Каждый день грузить всю историчность. Метка LOAD_DATE позволит версионировать Минусы - SSD/HDD - Ошибки в загрузках >1 дня Темпоральное Логическое Каждый день загружаем только новые данные. Заводим метки date_begin и date_end. Минусы - Сложность Каждый день загружаем только новые данные. На старые и обновленные вешаем метку is_deleted Минусы - Долго ЛИБО сложно
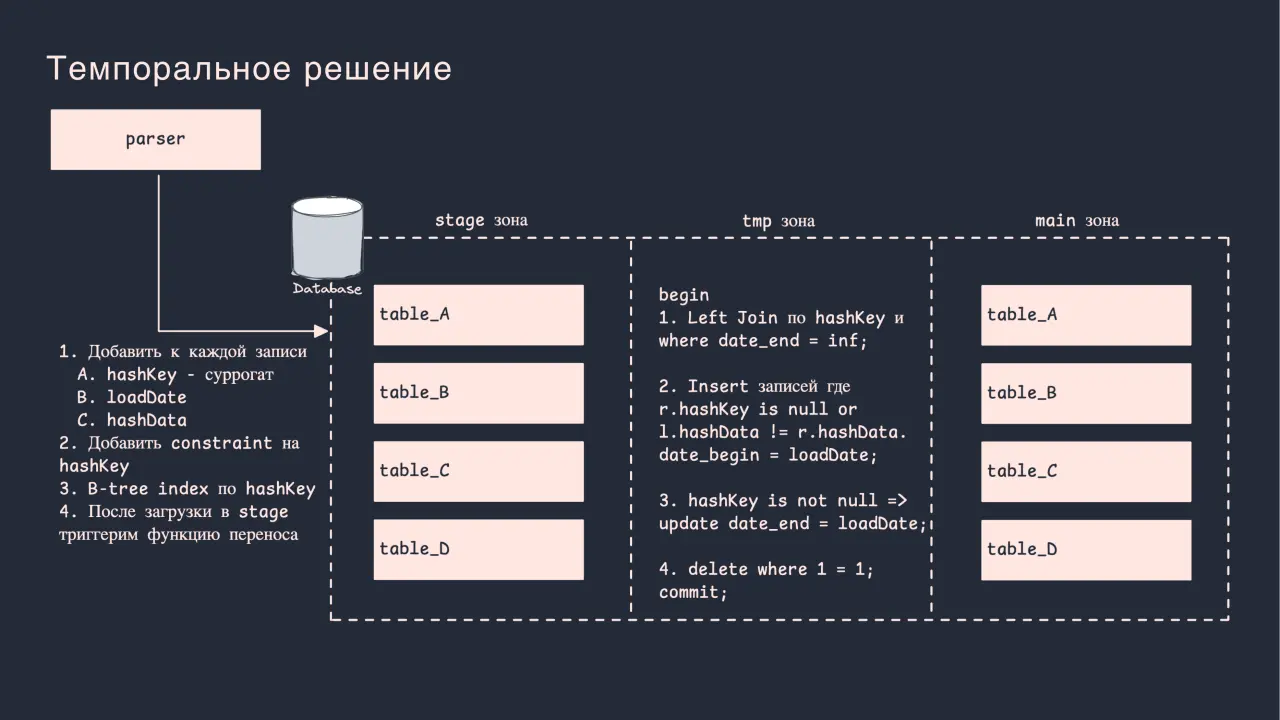
Слайд 18: Темпоральное решение
Темпоральное решение
Слайд 19: Спустя время
Спустя время
Слайд 20: Сотрудники стали мечтать о жизни без связей
Сотрудники стали мечтать о жизни без связей Спустя время
Слайд 21: Спустя время
Спустя время Сотрудники стали мечтать о жизни без связей И мы решили им в этом помочь
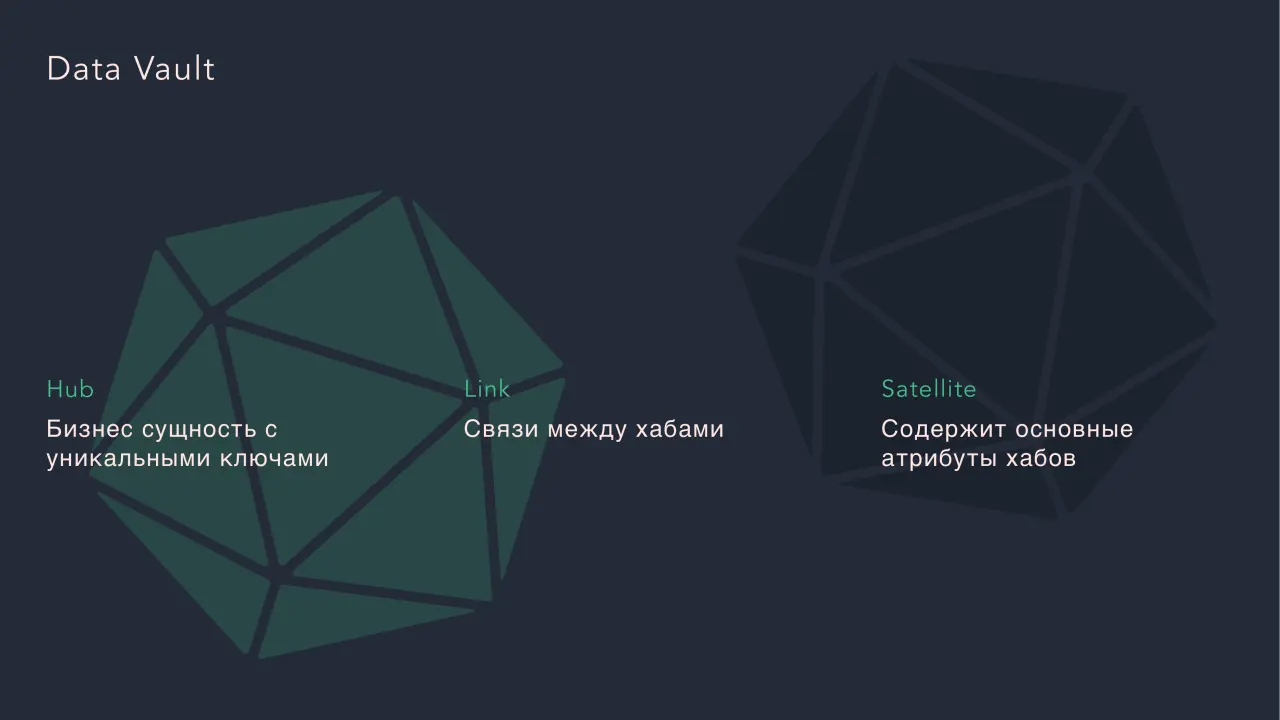
Слайд 22: Data Vault
Data Vault Hub Бизнес сущность с уникальными ключами Satellite Содержит основные атрибуты хабов Link Связи между хабами
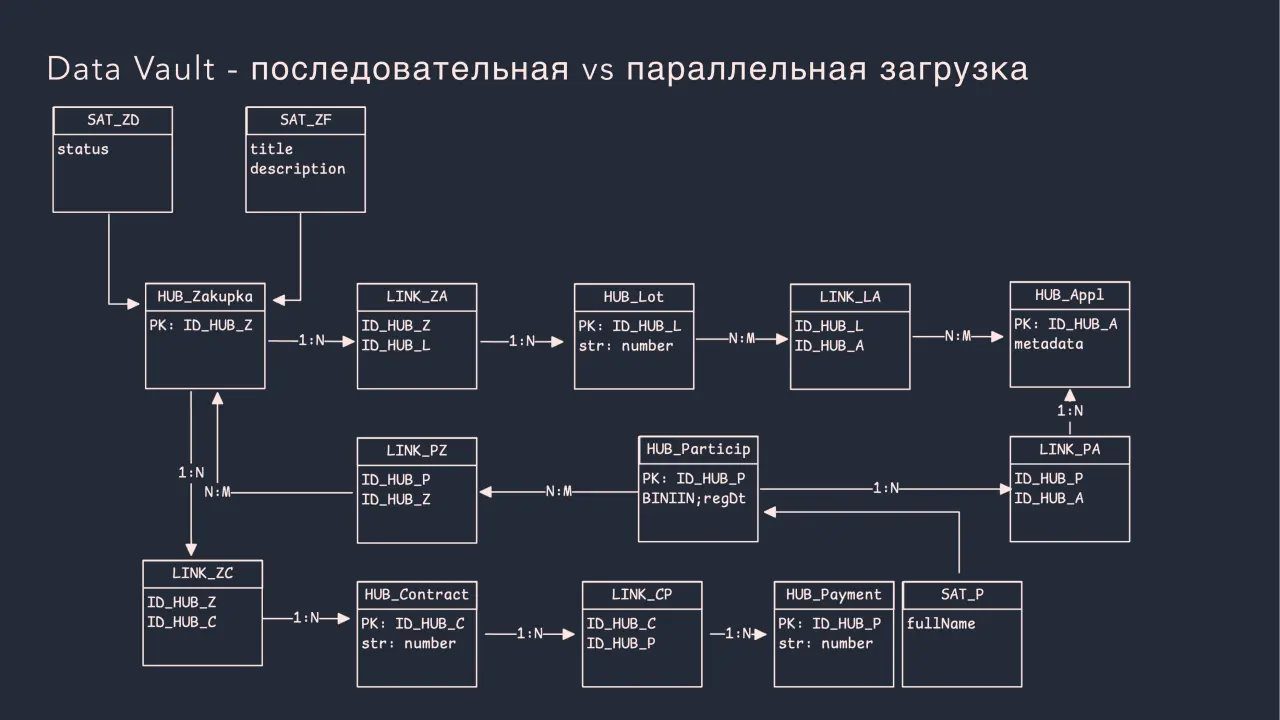
Слайд 23: Data Vault - последовательная vs параллельная загрузка
Data Vault - последовательная vs параллельная загрузка
Слайд 24: Стало много таблиц
Стало много таблиц
Слайд 25: Стало много таблиц
Стало много таблиц Изменения разработчиков конфликтуют
Слайд 26: Стало много таблиц
Стало много таблиц Изменения разработчиков конфликтуют Что делать? Как администрировать?
Слайд 27: Миграции и Flyway
Миграции и Flyway Миграция Любое изменение сделанное по отношению к базе данных. Бывают R - repeatable, V - versioned и U - undo. Schema history Специальная таблица, содержащая мета- информацию о примененных миграциях
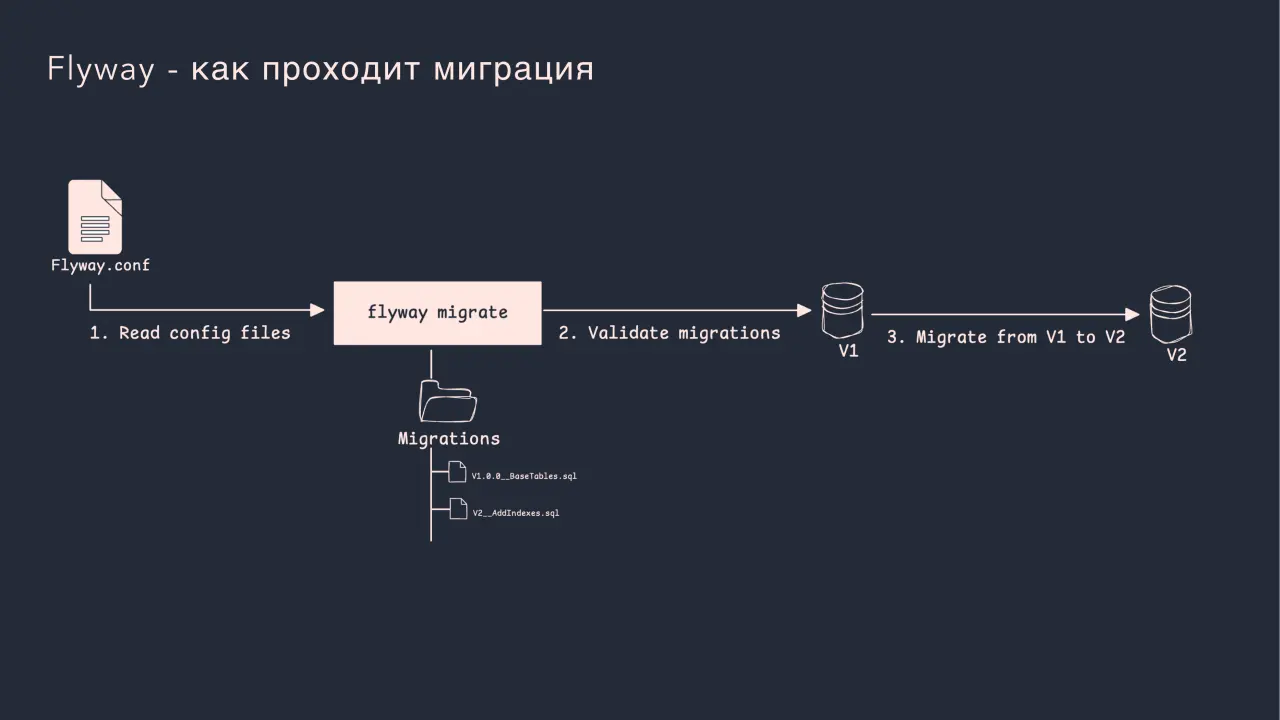
Слайд 28: Flyway - как проходит миграция
Flyway - как проходит миграция
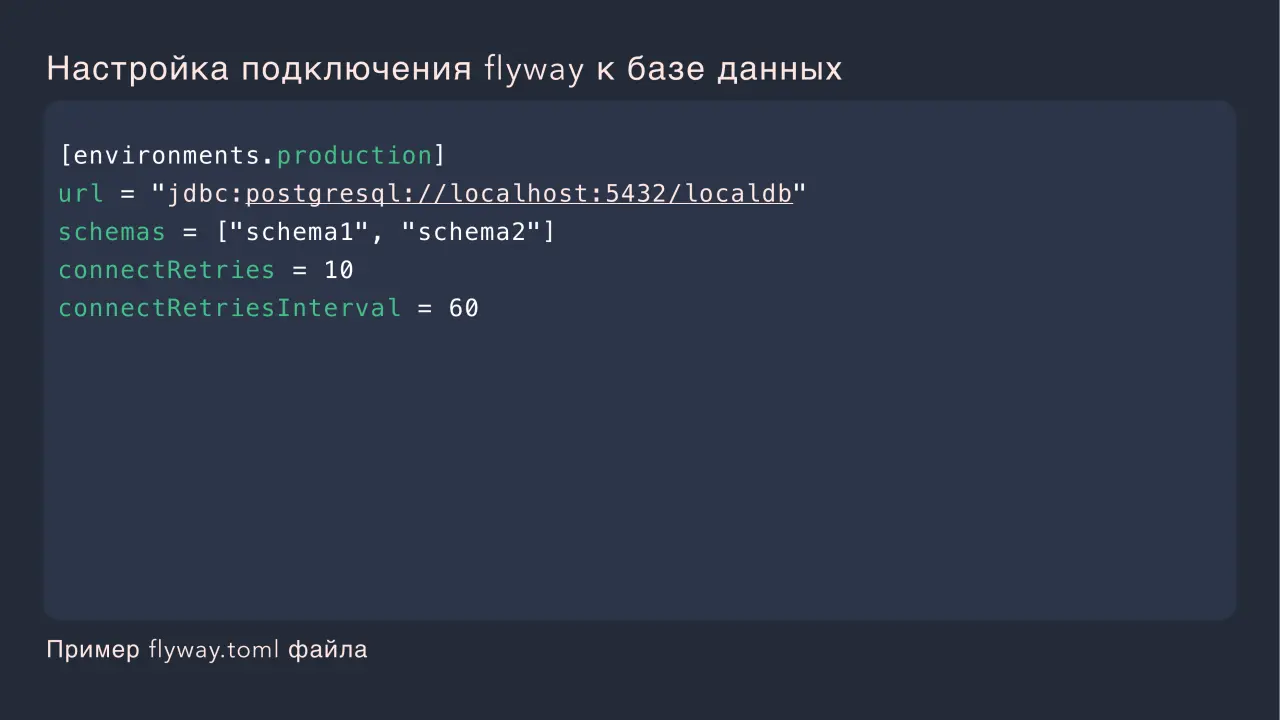
Слайд 29: Настройка подключения flyway к базе данных
Настройка подключения flyway к базе данных [environments.production] url = "jdbc:postgresql://localhost:5432/localdb" schemas = ["schema1", "schema2"] connectRetries = 10 connectRetriesInterval = 60 Пример flyway.toml файла
Слайд 30: База упала
База упала И данные пропали
Слайд 31: Способ избежать потерю данных - репликация
Способ избежать потерю данных - репликация Асинхронная репликация Применяем изменения на основном сервере, затем отправляем данные на реплики. Не ждем пока реплики применят изменения, но можем потерять часть данных Синхронная репликация Изменения сначала записываются хотя бы на одной реплике и только после этого фиксируются на основном сервере. Медленнее, но надежнее
Слайд 32: Virtual IP (VIP) -
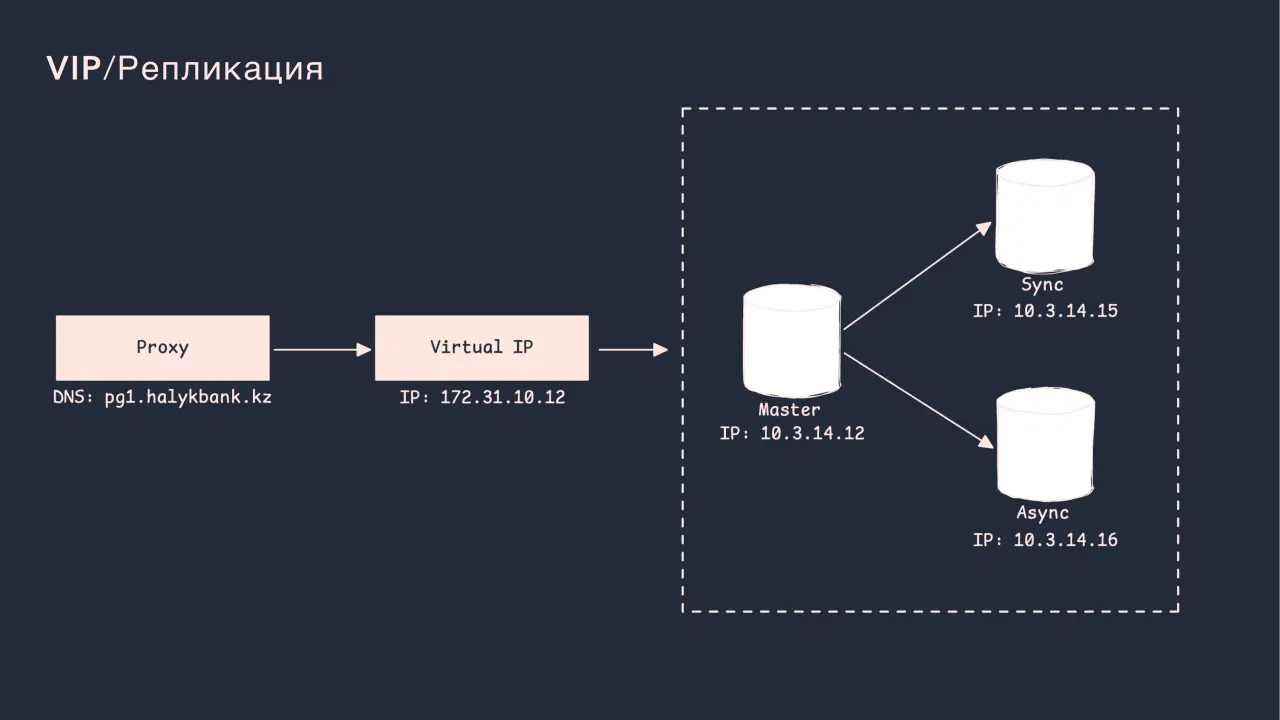
Virtual IP (VIP) - чтобы всегда обращаться по 1-му адресу
Слайд 33: VIP/Репликация
VIP/Репликация
Слайд 34: А почему данных нет в этой базе? А в этой?
А почему данных нет в этой базе? А в этой? Как доставить данные до других баз?
Слайд 35: Подход - junior. Грузить напрямую
Подход - junior. Грузить напрямую Будем грузить прямо из парсера данные сразу во все целевые базы. Да, прямой и простой способ, но - Повышается время работы при увеличении кол-ва баз данных - Компоненты становятся сильно связанными - Тяжело масштабировать процесс
Слайд 36: Подход - middle. Грузить через прослойку
Подход - middle. Грузить через прослойку Давайте грузить данные через прослойку, такую как Kafka Да, нагружаем сеть и +1 компонент на каждый источник. Но, имеем - Надежный и масштабируемый способ - Меньшая связность - Оптимальное время работы
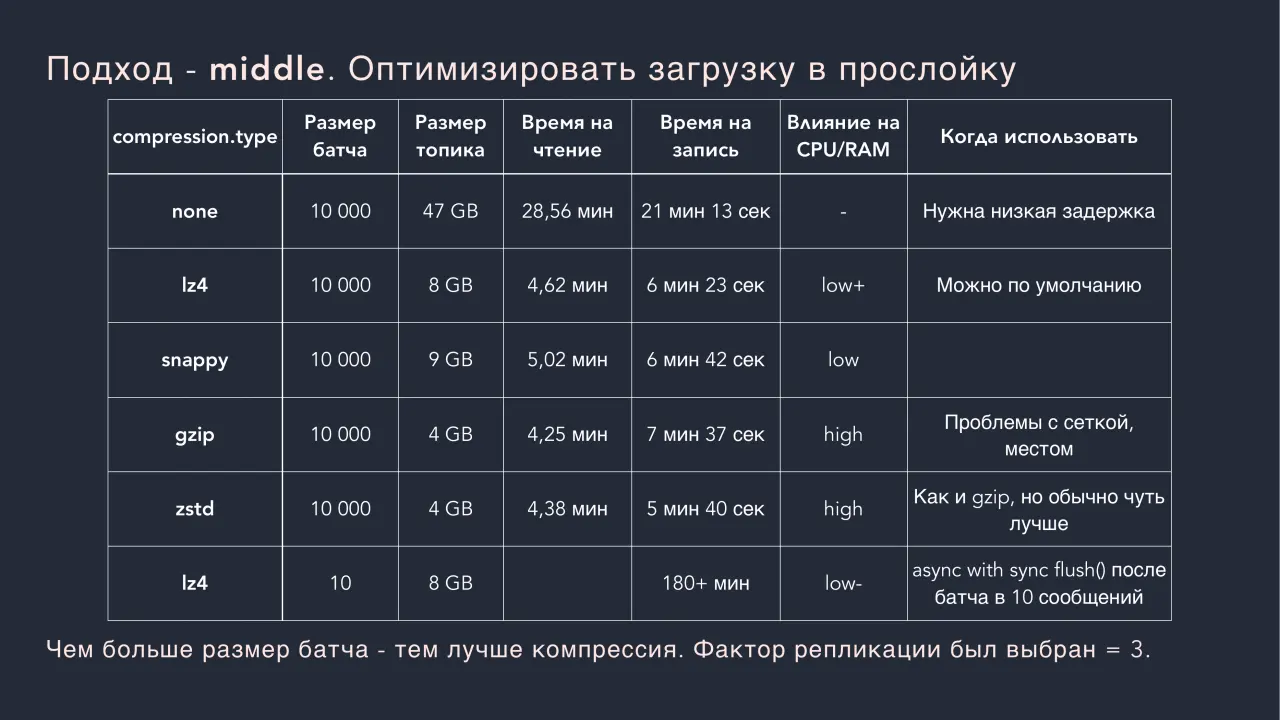
Слайд 37: Подход - middle. Оптимизировать загрузку в прослойку
Подход - middle. Оптимизировать загрузку в прослойку compression.type Размер батча Размер топика Время на чтение Время на запись Влияние на CPU/RAM Когда использовать none 10 000 47 GB 28,56 мин 21 мин 13 сек - Нужна низкая задержка lz4 10 000 8 GB 4,62 мин 6 мин 23 сек low+ Можно по умолчанию snappy 10 000 9 GB 5,02 мин 6 мин 42 сек low gzip 10 000 4 GB 4,25 мин 7 мин 37 сек high Проблемы с сеткой, местом zstd 10 000 4 GB 4,38 мин 5 мин 40 сек high Как и gzip, но обычно чуть лучше lz4 10 8 GB 180+ мин low- async with sync flush() после батча в 10 сообщений Чем больше размер батча - тем лучше компрессия. Фактор репликации был выбран = 3.
Слайд 38: Подход - middle. Регулируем гарантии доставки
Подход - middle. Регулируем гарантии доставки Sync Ждем подтверждения о доставке. Использовать только когда нужны 100%-ые гарантии доставки. Влияет на клиента Async Не ждем подтверждения доставки. Вешаем callback для обработки ошибок и гарантий доставки Fire and forget Не доставилось? Ну и ладно. Я даже не понял этого Например - для замера метрик
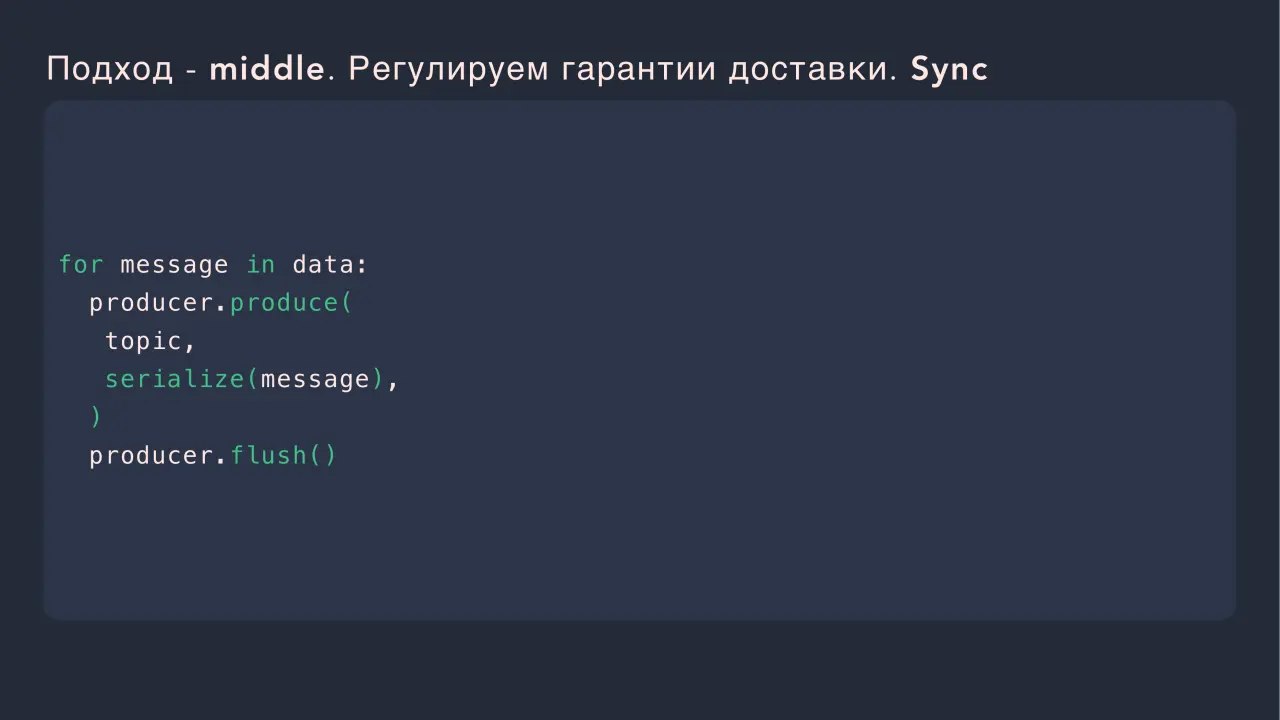
Слайд 39: Подход - middle. Регулируем гарантии доставки. Sync
Подход - middle. Регулируем гарантии доставки. Sync for message in data: producer.produce( topic, serialize(message), producer.flush()
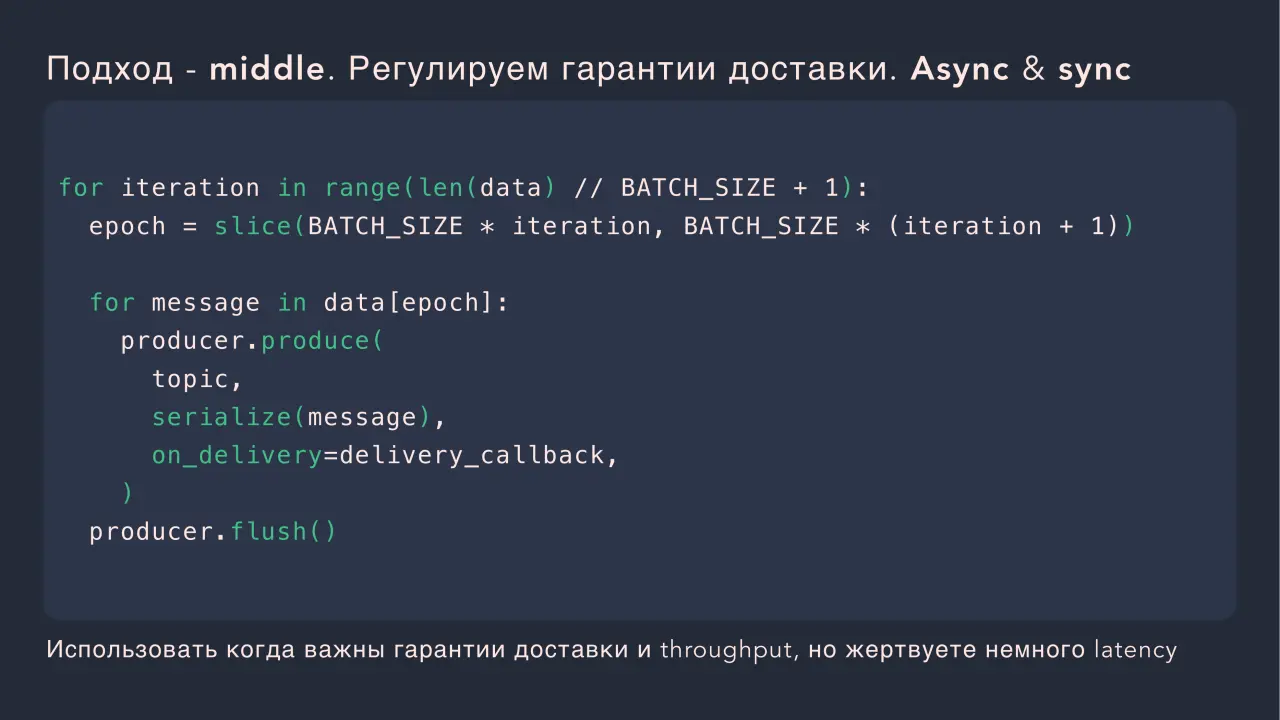
Слайд 40: Подход - middle. Регулируем гарантии доставки. Async & sync
Подход - middle. Регулируем гарантии доставки. Async & sync Использовать когда важны гарантии доставки и throughput, но жертвуете немного latency for iteration in range(len(data) // BATCH_SIZE + 1): epoch = slice(BATCH_SIZE * iteration, BATCH_SIZE * (iteration + 1)) for message in data[epoch]: producer.produce( topic, serialize(message), on_delivery=delivery_callback, producer.flush()
Слайд 41: Кое что забыли…
Кое что забыли…
Слайд 42: Как будем синхронизировать завершение
Как будем синхронизировать завершение загрузки в Кафку/загрузку из Кафки? Кое что забыли…
Слайд 43: Как будем синхронизировать завершение
Как будем синхронизировать завершение загрузки в Кафку/загрузку из Кафки? Кое что забыли…
Слайд 44: Много топиков и учетных записей. Что делать?
Много топиков и учетных записей. Что делать?
Слайд 45: Декларативность
- Декларативность - Воспроизводимость кластера - Версионирование Terraform - Mongey/Kafka для администрирования кластера Разработчики - сами могут получить необходимое
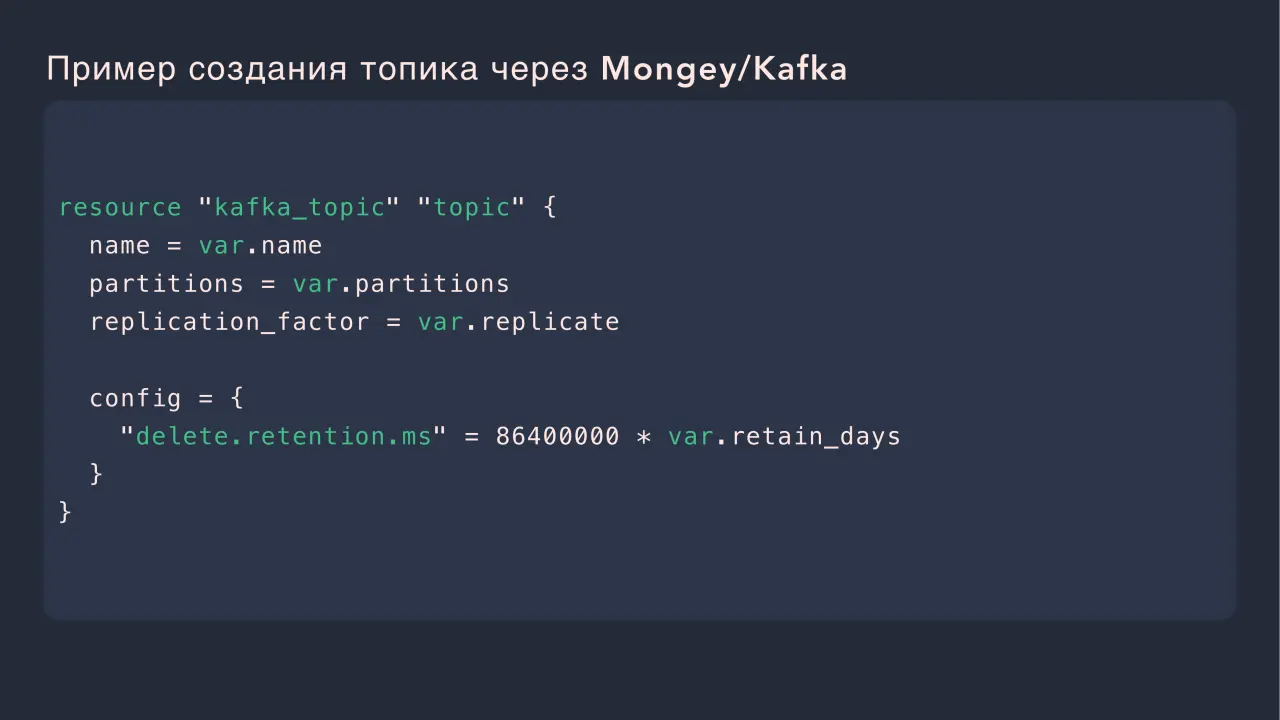
Слайд 46: Пример создания топика через Mongey/Kafka
Пример создания топика через Mongey/Kafka resource "kafka_topic" "topic" { name = var.name partitions = var.partitions replication_factor = var.replicate config = { "delete.retention.ms" = 86400000 * var.retain_days
Слайд 47: Бонус: как дедублицировать через БД?
Бонус: как дедублицировать через БД?
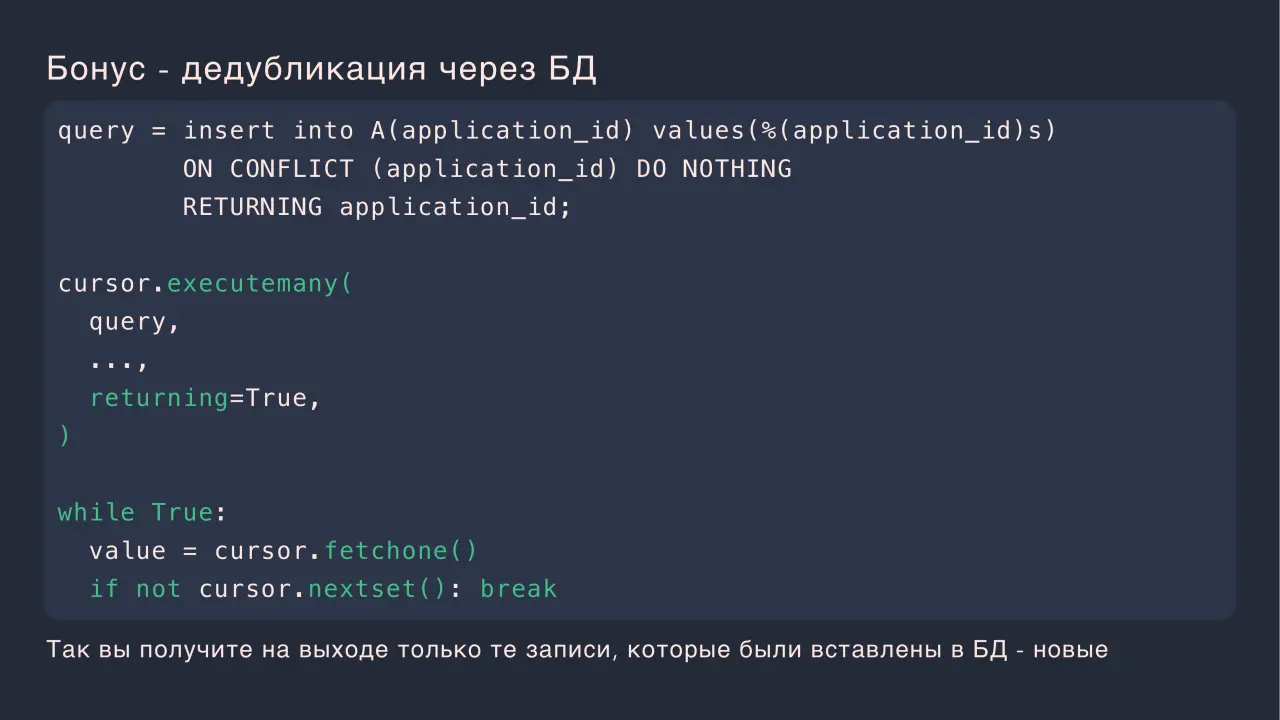
Слайд 48: Бонус - дедубликация через БД
Бонус - дедубликация через БД Так вы получите на выходе только те записи, которые были вставлены в БД - новые query = insert into A(application_id) values(%(application_id)s) ON CONFLICT (application_id) DO NOTHING RETURNING application_id; cursor.executemany( query, returning=True, while True: value = cursor.fetchone() if not cursor.nextset(): break
Слайд 49: Спасибо за внимание
Спасибо за внимание Ссылка на материалы
Другие доклады митапа
- Д
- АГПрименение и оптимизация работы LLM. RAG, борьба с галлюцинациями Азамат Галимжанов
- ДТCelery — Best Practices Даурен Талгатулы

