RAG vs Fine-tuning vs Agents
Почему одни LLM-системы решают задачи, а другие уверенно выдумывают ответы? RAG, fine-tuning и агенты — это не три «обязательных шага», а три разных инструмента под разные задачи. Проблема в том, что их часто выбирают по тренду, а не по необходимости: из-за этого системы либо не дают эффекта, либо становятся излишне сложными.
Хайдар Булхайыр — лид AI-команды во Freedom Travel. За его плечами антифрод в Kaspi, спортивная аналитика, банковский data science, работа в стартапе на стыке CV, аналитики и инженерии, AI-архитектура в qCloudy.
В докладе: — что такое RAG, fine-tuning и агенты и с чем их едят — в каких задачах RAG реально работает, а где нет — когда стоит идти в fine-tuning — где агенты дают ценность, а где только добавляют сложность — как правильно связать LLM и классический ML
Видео
Презентация
 1 / 30
1 / 30



























Текст презентации
Слайд 1: ALMATY PYTHON MEETUP #7
ALMATY PYTHON MEETUP #7 RAG · Fine-tune · Агенты Когда что выбирать и как не сломаться в проде Хайдар Булхайыр AI Lead, Freedom Travel · @HaidarBulk
Слайд 2: Знакомая ситуация?
Знакомая ситуация? Три частых сценария, где всё пошло не туда «Прикрутим RAG к базе знаний» Прикрутили. Точность 38%. Менеджеры жалуются, что бот тупой и путает документы. «Файнтюним LLaMA на наших данных» Недели обучения. Модель забыла, что такое вежливость, но выучила внутренний жаргон. «Сделаем агента, он сам разберётся» Агент уверенно вызвал не тот API, удалил тестовые данные и сжёг $400 на токены. Проблема не в инструментах — в том, как их выбирают.
Слайд 3: О чём поговорим
О чём поговорим Семь коротких блоков 1 RAG, fine-tune, агенты: что это по факту Когда что использовать — фреймворк выбора 3 Почему RAG не работает и как чинить 4 Fine-tuning: когда стоит и сколько это стоит Агенты: где ценность, где просто сложность 6 Архитектура в проде + LLMOps LLM и классический ML: как они живут вместе
Слайд 4: Простая аналогия
Простая аналогия Представьте: LLM — это толковый, но новый сотрудник RAG доступ к корпоративной вики Умный, но ваших документов не видел. Дайте искать и читать — тогда отвечает по фактам. Fine-tuning научить говорить как ваша компания Меняет манеру: стиль, формат, тон, специфический язык. Знания почти не меняются. Агенты дать руки и право действовать Не только отвечает, но и делает: открывает тикеты, ищет данные, запускает процессы.
Слайд 5: РАЗДЕЛ 1
РАЗДЕЛ 1 Сравнение и выбор RAG vs Fine-tune vs Агенты
Слайд 6: Сравнение по шести параметрам
Сравнение по шести параметрам Одна задача, три инструмента — цена и эффект разные RAG Fine-tune Агенты Что меняет Знания модели Поведение модели Действия системы Срок до прода Дни Недели + датасет Дни PoC, месяцы прод Цена за запрос Низкая Очень низкая Высокая Время отклика 1–3 сек < 1 сек 5–30 сек Контроль Высокий Средний Низкий Главный риск Плохой поиск Деградация модели Каскад ошибок
Слайд 7: Когда что выбирать
Когда что выбирать Задайте себе: чего не хватает модели? Что нужно изменить? Знания → RAG Документы, регламенты, база знаний. Всё, что можно найти и процитировать. Поведение и стиль → Промпт, затем Fine-tune Сначала промпт + few-shot. Тюн — только если прошлый шаг не решил. Действия в мире → Function call, затем Агент Пайплайн с вызовами. Агент — когда цепочка реально ветвится. До любого из них проверьте: решается ли задача хорошим промптом или классическим ML?
Слайд 8: РАЗДЕЛ 2
РАЗДЕЛ 2 Почему RAG не работает И как сделать, чтобы работал
Слайд 9: Как RAG устроен
Как RAG устроен Сначала найди — потом ответь Вопрос пользователь Поиск vector DB / search Контекст топ-N кусков Ответ LLM по найденному LLM не знает ваши данные Что не попало в контекст — для модели не существует.
Слайд 10: Пять причин, почему RAG не работает
Пять причин, почему RAG не работает Почти всегда виноват pipeline вокруг LLM, а не сама модель Грязные данные Дубли, разные версии одного документа, отменённые регламенты вперемешку с актуальными. RAG найдёт мусор — и уверенно перескажет. Глупый chunking Резка по 512 токенов рвёт смысл посреди предложения. Половина чанков теряет контекст и становится бесполезной. Только векторный поиск Эмбеддинги ловят смысл, но плохо ищут точные термины, номера, аббревиатуры. Нужна гибридная схема. Нет метаданных Нельзя отфильтровать по дате, версии, типу. Бот цитирует регламент, отменённый два года назад. Нет переранжирования Топ-5 от первичного поиска часто не лучшие. Cross-encoder сверху меняет картину.
Слайд 11: Кейс: «бот по базе знаний», который не
Кейс: «бот по базе знаний», который не работал Имена и цифры слегка обобщены Запрос от бизнеса «Сделайте RAG-бота по 12 000 PDF, пусть отвечает менеджерам» Сделали по учебнику Чанки 512 токенов, OpenAI embeddings, GPT-4 сверху. MVP за неделю. Запустили: точность 38% Бот выдумывает суммы, путает версии договоров, цитирует неактуальные регламенты. Дошли до 81% Чистка дублей · метаданные (дата, версия) · гибридный поиск (BM25 + векторный) · переранжирование · структурный chunking В RAG 80% работы — это данные и поиск. Не LLM сверху.
Слайд 12: Чек-лист правильного RAG
Чек-лист правильного RAG Закрыта половина пунктов — уже выше среднего Данные почищены Дубли удалены, актуальные версии помечены, мусор отфильтрован. Структурный chunking Режем по разделам и пунктам, не по токенам. Контекст сохраняется. Метаданные у чанков Дата, версия, тип, автор. Чтобы можно было фильтровать при поиске. Гибридный поиск BM25 для точных терминов + векторный для смысла. Слияние результатов. Переранжирование Cross-encoder сверху пересортирует топ-N от первичного поиска. Метрики и оценка Не «вроде отвечает», а precision/recall на тестовом сете.
Слайд 13: РАЗДЕЛ 3
РАЗДЕЛ 3 Fine-tuning Правда об экономике
Слайд 14: Fine-tuning: когда делать, когда точно нет
Fine-tuning: когда делать, когда точно нет «Зафайнтюним — модель выучит наши данные». Нет. Стоит, когда… Нужен жёсткий формат вывода (своя JSON- схема) Промпт раздулся до 2–3K токенов и повторяется Узкий домен с устойчивой терминологией Latency и cost критичны, нужна маленькая модель Не стоит, когда… Хотите «добавить знания» — это работа RAG Меньше 500–1000 качественных примеров Данные часто меняются Не пробовали prompt engineering Простое правило: RAG — для знаний, fine-tune — для поведения.
Слайд 15: Кейс: «зафайнтюним — будет дешевле»
Кейс: «зафайнтюним — будет дешевле» Разбираем иллюзию 3 нед на сбор и разметку качественного датасета GPU-часы + цикл «обучили → проверили → переобучили» это не волшебство: меняете боль промпта на боль датасета Перед тем как тратить недели — пройдите чек-лист: Хороший промпт + few-shot примеры Структурный вывод (JSON-схемы, function calling) RAG — если проблема в недостающих знаниях Если ничего не сработало — только тогда fine-tune
Слайд 16: РАЗДЕЛ 4
РАЗДЕЛ 4 Агенты Ценность и сложность. Где проходит граница
Слайд 17: Цикл агента и математика ошибок
Цикл агента и математика ошибок Каждый шаг — потенциальная точка отказа Цикл Цель что нужно сделать План шаги и инструменты Действие вызов API / поиск / код Наблюдение что получилось Решение продолжить / переиграть Математика ошибок Если на одном шаге модель ошибается с вероятностью 5 шагов успех 77% 10 шагов успех 60% 15 шагов успех 46% 20 шагов успех 36%
Слайд 18: Где агенты дают ценность, где — только
Где агенты дают ценность, где — только сложность Один большой агент vs набор простых пайплайнов Было: «универсальный агент» Один агент, всё в одном 8–12 LLM-вызовов на запрос Latency 15–25 сек, $0.20+ за диалог Чёрный ящик: выбор объяснить нельзя Стало: пайплайны + узкий агент Поиск и фильтры — обычный пайплайн Ранжирование — классический ML LLM — только там, где нужен язык Latency ~3 сек, в 5–7 раз дешевле
Слайд 19: РАЗДЕЛ 5
РАЗДЕЛ 5 AI-ассистент в проде Как собрать архитектуру и что измерять
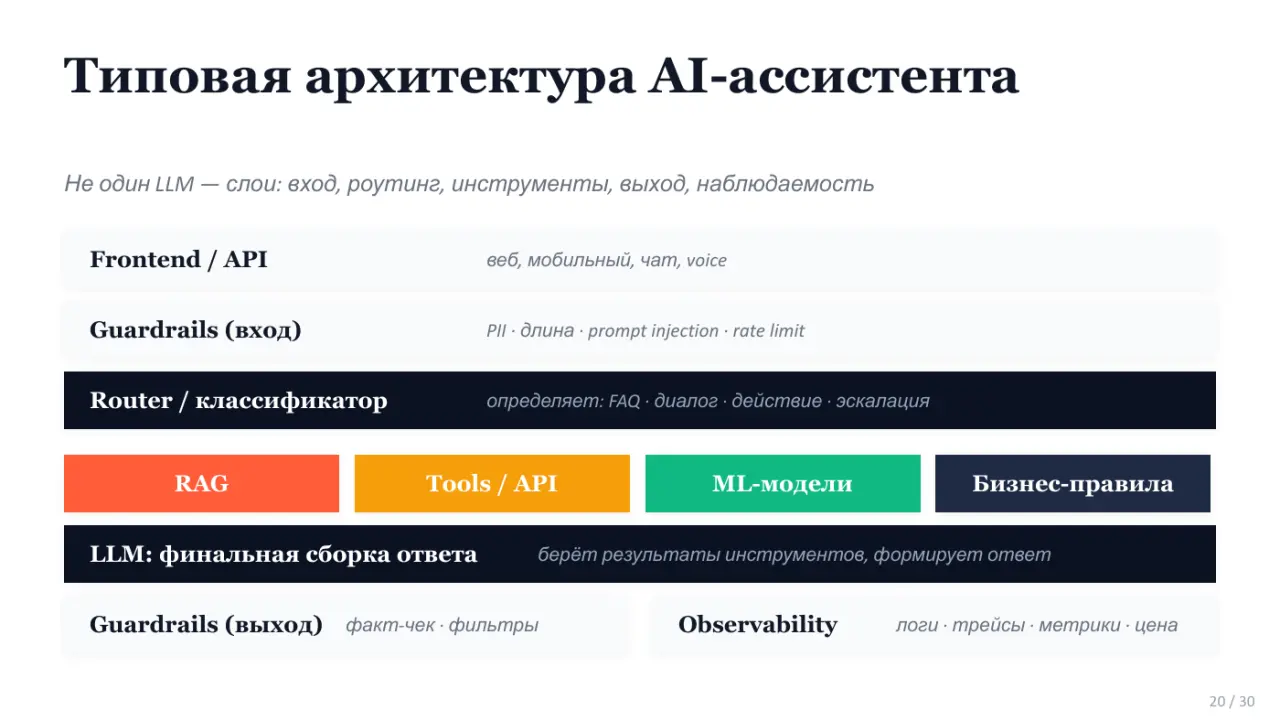
Слайд 20: Типовая архитектура AI-ассистента
Типовая архитектура AI-ассистента Не один LLM — слои: вход, роутинг, инструменты, выход, наблюдаемость Frontend / API веб, мобильный, чат, voice Guardrails (вход) PII · длина · prompt injection · rate limit Router / классификатор определяет: FAQ · диалог · действие · эскалация RAG Tools / API ML-модели Бизнес-правила LLM: финальная сборка ответа берёт результаты инструментов, формирует ответ Guardrails (выход) факт-чек · фильтры Observability логи · трейсы · метрики · цена
Слайд 21: Шесть типовых ошибок при сборке
Шесть типовых ошибок при сборке С чем сталкиваются почти все, кто запускает LLM в прод «Один LLM на всё» Без роутинга простые вопросы идут через большую модель. Дорого, медленно, нестабильно. Нет fallback LLM упал или вернул мусор — диалог обрывается. Нужен план Б: правила, кэш, эскалация. Не считают цену Запустили, через неделю — шок от счёта. Cost per request нужно мерить с первого дня. Нет наблюдаемости Без логов и трейсов нельзя понять, почему диалог сломался. Дебаг невозможен. Промпт в коде, без версий Поменяли промпт, что-то сломалось, откатить нельзя. Промпт — это код, ему нужен git. Нет evaluation Меряют по ощущениям: «вроде стало лучше». Нужен тестовый сет и регулярные прогоны.
Слайд 22: Метрики RAG: что измерять
Метрики RAG: что измерять Отдельно — поиск, отдельно — ответ Retrieval · поиск Hit rate @ K доля запросов, где правильный документ в топ-K MRR · Recall @ K насколько высоко стоит правильный ответ Context precision сколько найденных кусков реально полезны Context recall не упустили ли важные куски Generation · ответ LLM Faithfulness не придумала ли модель факты сверх контекста Answer relevance отвечает ли ответ на сам вопрос Answer correctness совпадает ли с эталоном (на тестовом сете) Citation accuracy правильно ли указаны источники Инструменты: Ragas · TruLens · DeepEval · ручная разметка на 100–300 примерах
Слайд 23: Метрики Fine-tuning и Агентов
Метрики Fine-tuning и Агентов Правило: без сравнения с базой метрики бессмысленны Fine-tuning Eval set accuracy % правильных на тестовом сете (300+ примеров) Regression vs base не сломали ли то, что работало в базовой модели Format compliance % ответов в нужном формате (для JSON-схем) Cost per inference сколько стоит один запрос на проде Агенты Task success rate % диалогов, где задача решена end-to-end Steps per task медиана и хвост: 5 — норм, 30+ — красный флаг Tool call accuracy % правильных вызовов с правильными аргументами Cost per session $/диалог + распределение, не только среднее Без сравнения с базой (промпт, прошлая версия) любая метрика вводит в заблуждение.
Слайд 24: LLMOps: что трекать в проде каждый день
LLMOps: что трекать в проде каждый день Метрики качества — половина истории. Вторая половина — операционка. Latency p50, p95, p99 — не среднее. Хвост распределения убивает UX. Cost $/запрос, $/пользователь, $/день. Бюджетные алерты. Error rate По типам: timeout, tool failure, hallucination flag, refusal. Prompt versions Git для промптов. Какая версия дала какой ответ. Drift detection Качество и распределение запросов меняются со временем. User feedback Thumbs up/down + анализ жалоб. Это бесплатные метки. Стек: Langfuse · Helicone · Arize Phoenix · LangSmith · OpenTelemetry под LLM-трейсинг
Слайд 25: РАЗДЕЛ 6
РАЗДЕЛ 6 LLM + классический ML Не вместо, а вместе
Слайд 26: Какой инструмент для какой задачи
Какой инструмент для какой задачи У LLM и классического ML разные сильные стороны Задача Что подходит лучше Почему Скоринг, прогноз вероятности Классический ML Калибровка, интерпретируемость, скорость Извлечение данных из текста LLM Гибкость, не нужно учить под каждую форму Поиск по документам Embeddings + BM25 Дёшево и быстро на проде Решения по чётким правилам Бизнес-правила / деревья Предсказуемо, дёшево, аудируемо Диалог, объяснения, генерация LLM Только она это умеет хорошо Аномалии и фрод ML ловит, LLM объясняет Связка двух подходов В хорошей системе каждый инструмент делает своё.
Слайд 27: РАЗДЕЛ 7
РАЗДЕЛ 7 Финал Как выбирать и что унести с собой
Слайд 28: Фреймворк выбора: 4 вопроса перед
Фреймворк выбора: 4 вопроса перед стартом Короткая пауза здесь — бережёт месяцы работы потом Чего не хватает модели: знаний или поведения? Знаний → RAG. Поведения → промпт или fine-tune. Решает ли задачу хороший промпт + few-shot? Да → стоп, не усложняйте. Нет → идём дальше. Это один шаг или цепочка из 4–5+ действий? Один шаг → function call. Цепочка → возможно, агент. Можно ли решить классическим ML или правилами? Если да и качество ОК — берите ML. Дешевле, быстрее, надёжнее.
Слайд 29: Что унести с собой
Что унести с собой Пять фраз, которые стоит запомнить RAG — для знаний. Fine-tune — для поведения. Агенты — для действий. В RAG 80% работы — это данные и поиск. Не LLM сверху. Хороший промпт побеждает плохой fine-tune. Хороший AI-продукт — это оркестр инструментов, не один большой агент. LLM и классический ML работают вместе, а не друг против друга.
Слайд 30: Спасибо
Спасибо Вопросы? Готов обсудить ваш кейс — особенно если что-то пошло не по плану. Хайдар Булхайыр AI Lead, Freedom Travel Telegram @HaidarBulk LinkedIn hbulkhaiyr
Другие доклады митапа
- ЕАЭволюция ИИ-агентов: OpenClaw, Hermes и новые подходы Елдан Абдрашим
- АГAgentic engineering Азамат Галимжанов
- МХНе всегда нужна LLM: Data-to-Text, ETL и 10b.kz Мадияр Хамзанов

