LLM в продакшне

LLM в демке и LLM в проде — две очень разные истории.
Азамат Галимжанов разбирает одну из самых горячих тем — LLM в продакшне.
В докладе: — как эффективно использовать большие языковые модели в реальных проектах — как их поддерживать в продакшне
Презентация
 1 / 31
1 / 31







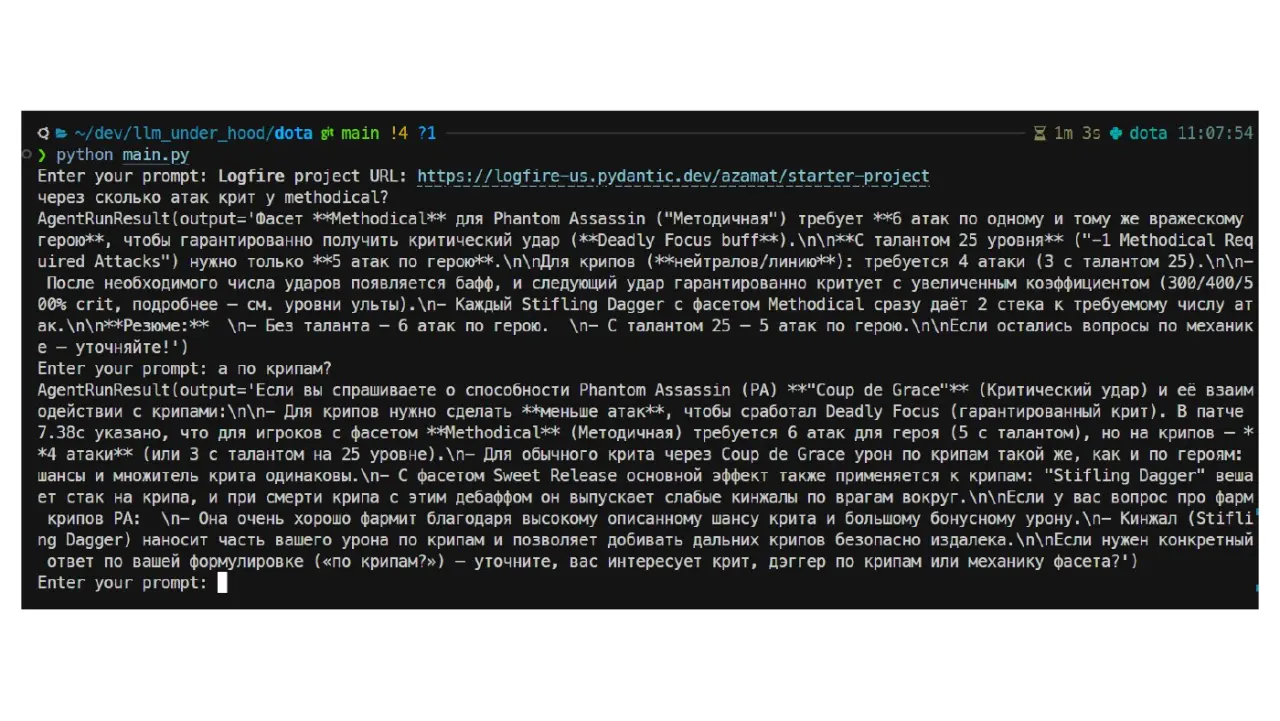
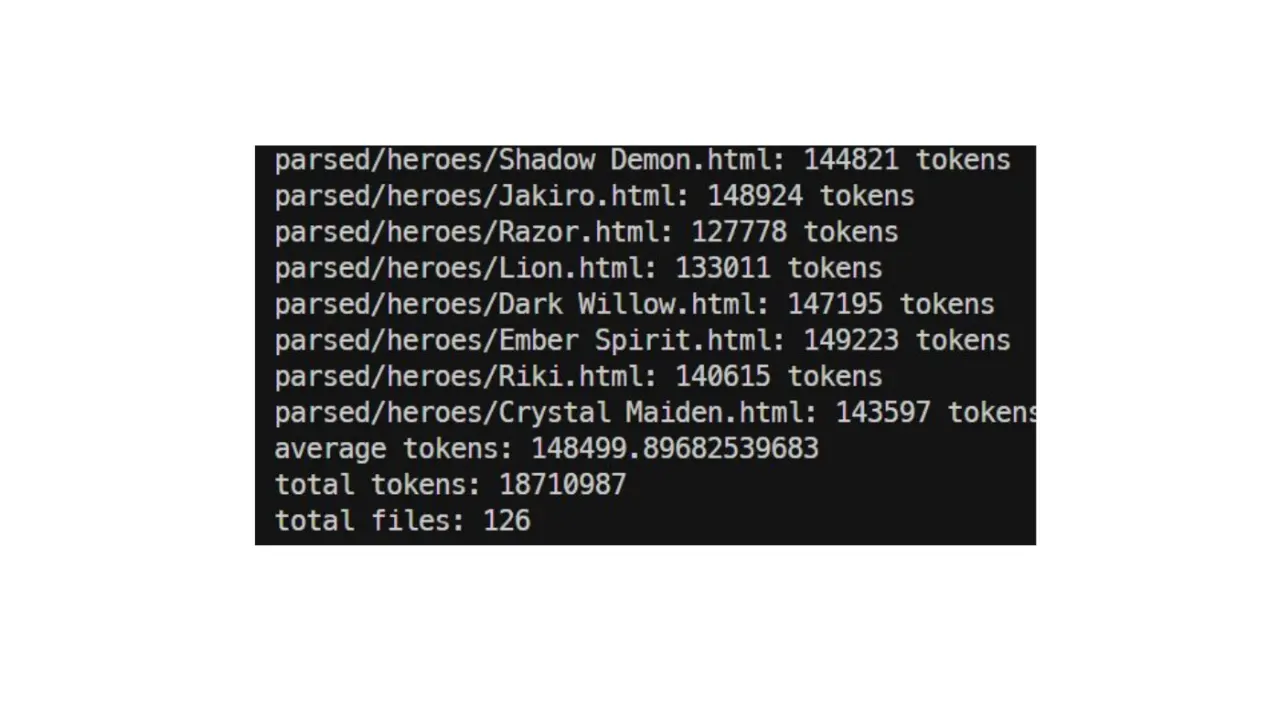
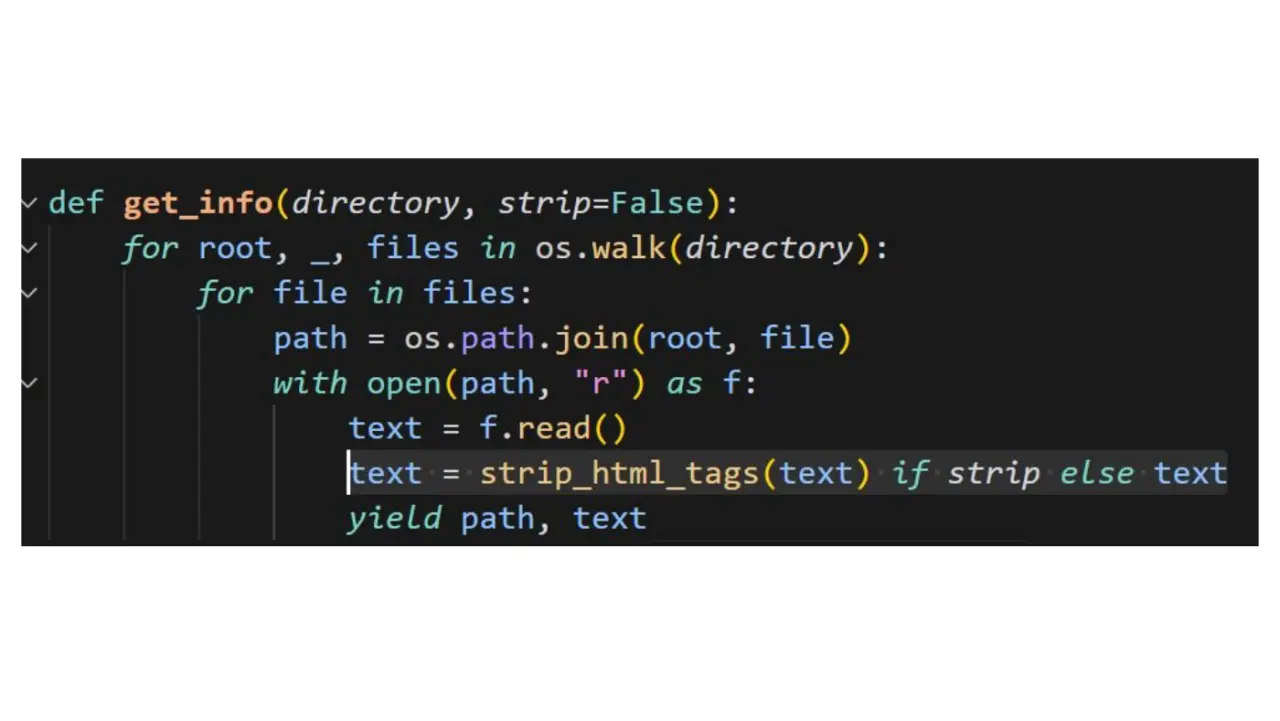
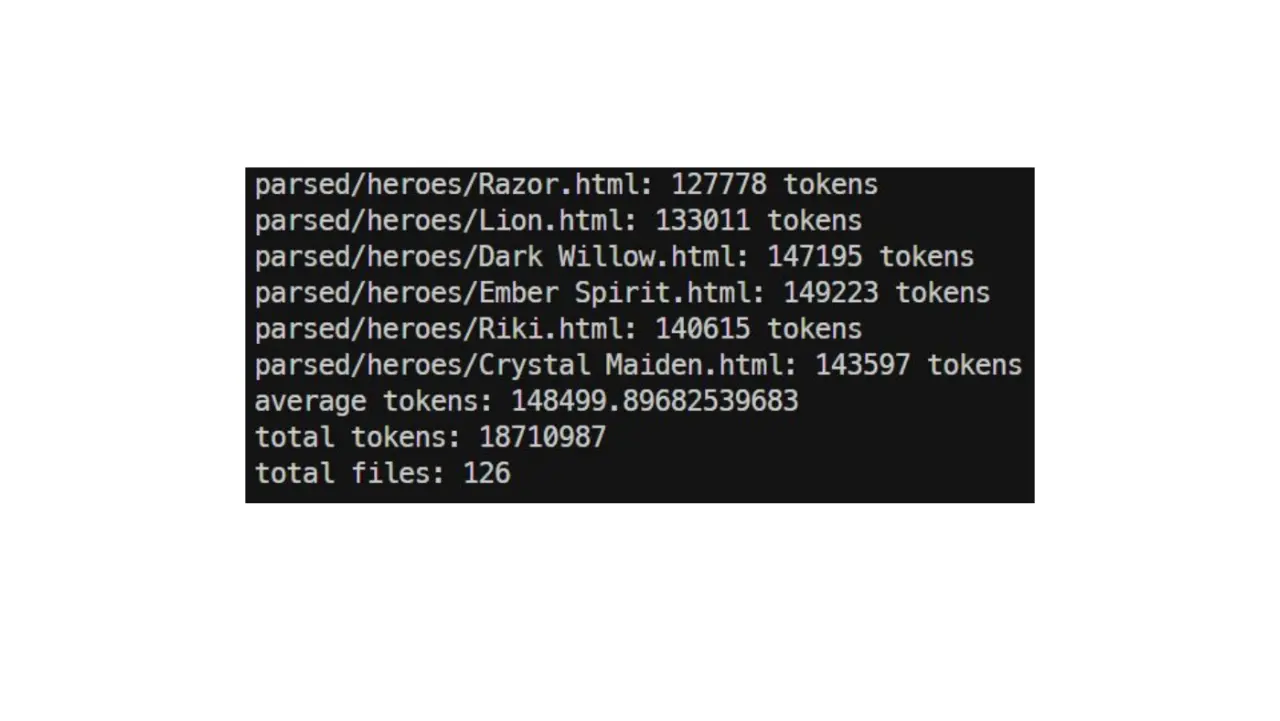

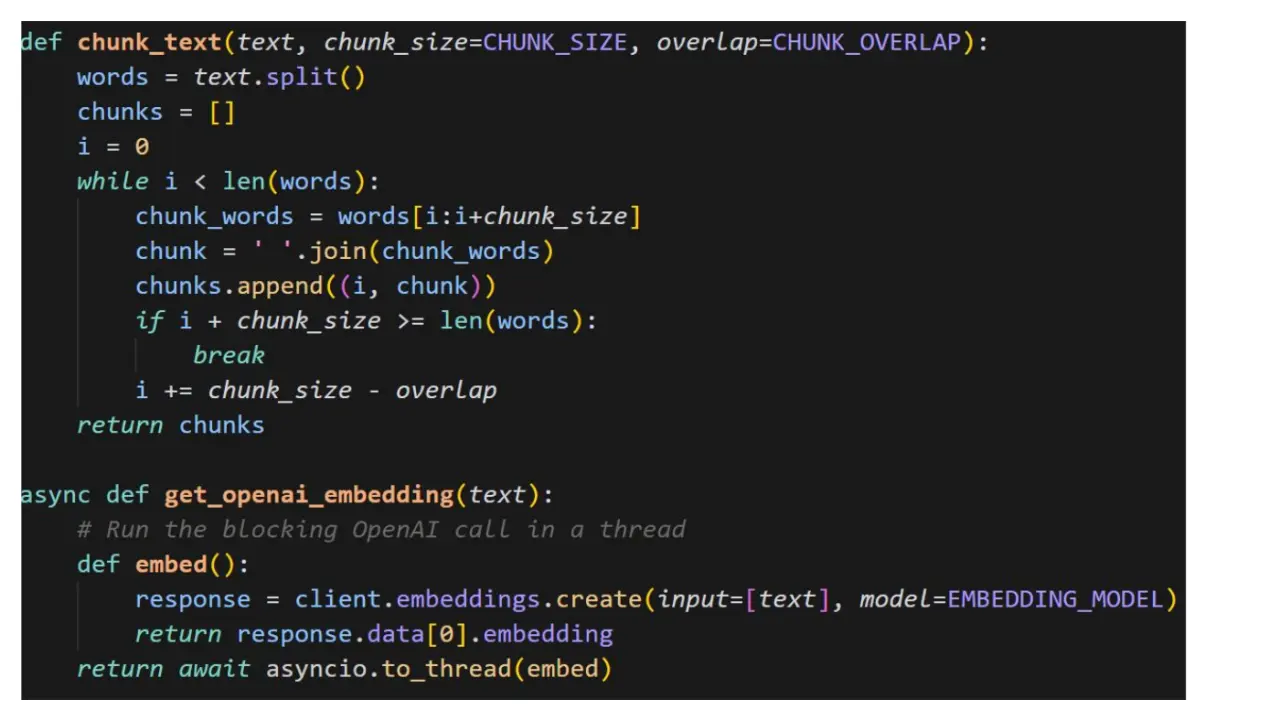





Текст презентации
Слайд 1: LLM в Продакшене
LLM в Продакшене Практики Борьбы с Галлюцинациями Азамат Галимжанов
Слайд 2: Азамат Галимжанов
Азамат Галимжанов - Профессиональный разработчик с 2007 - Изучаю AI \ ML с 2011 - Стартапы гдематериал, biometric.vision - Занимаюсь generative AI с 2022 @aza_ai_expert
Слайд 5: Галлюцинации
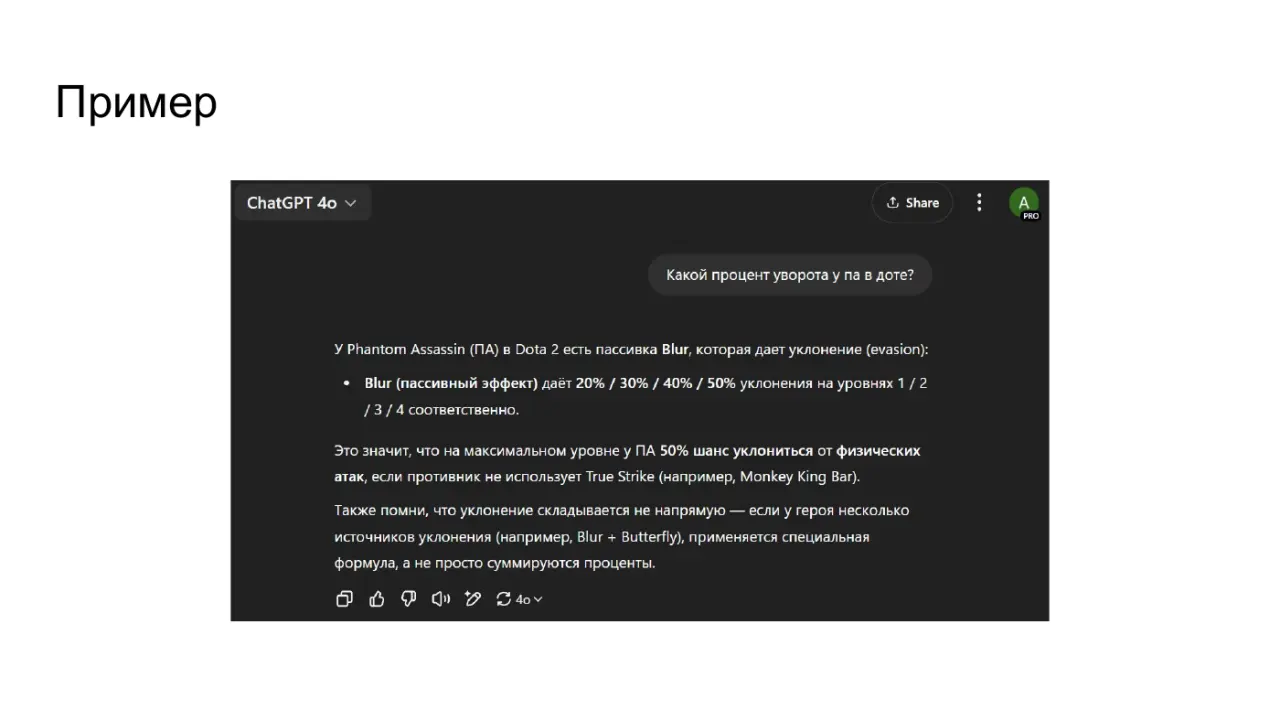
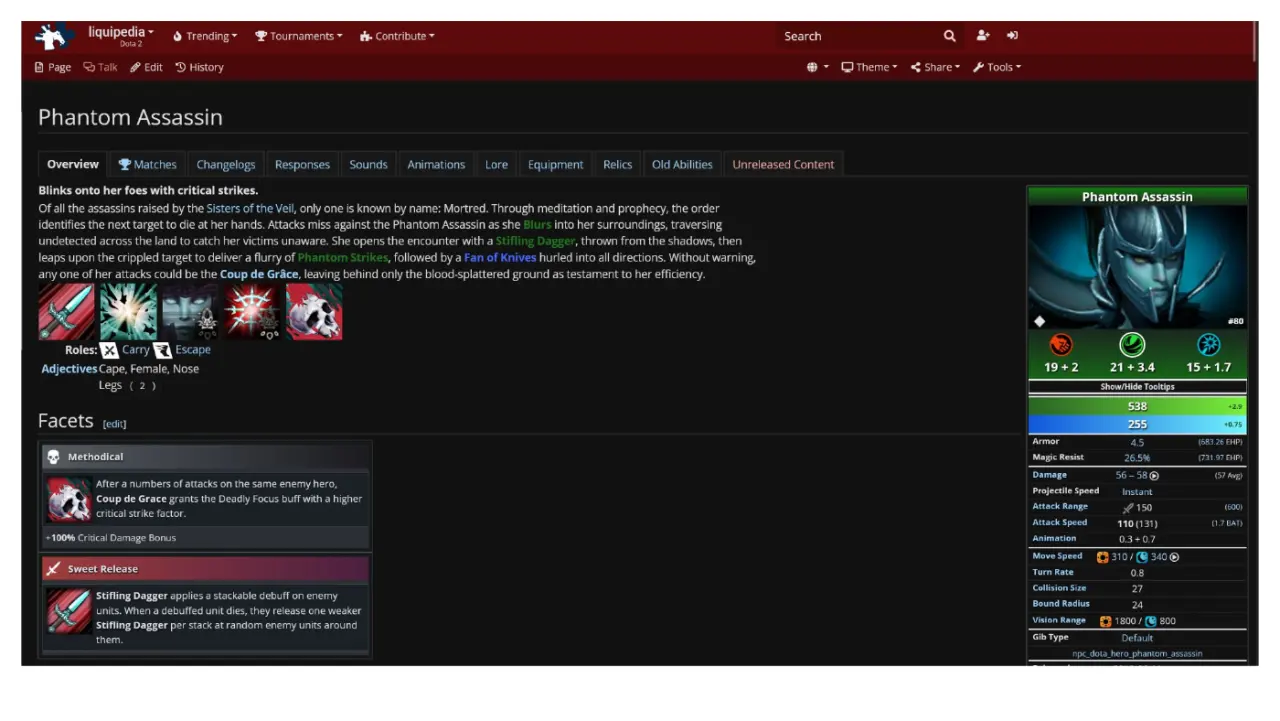
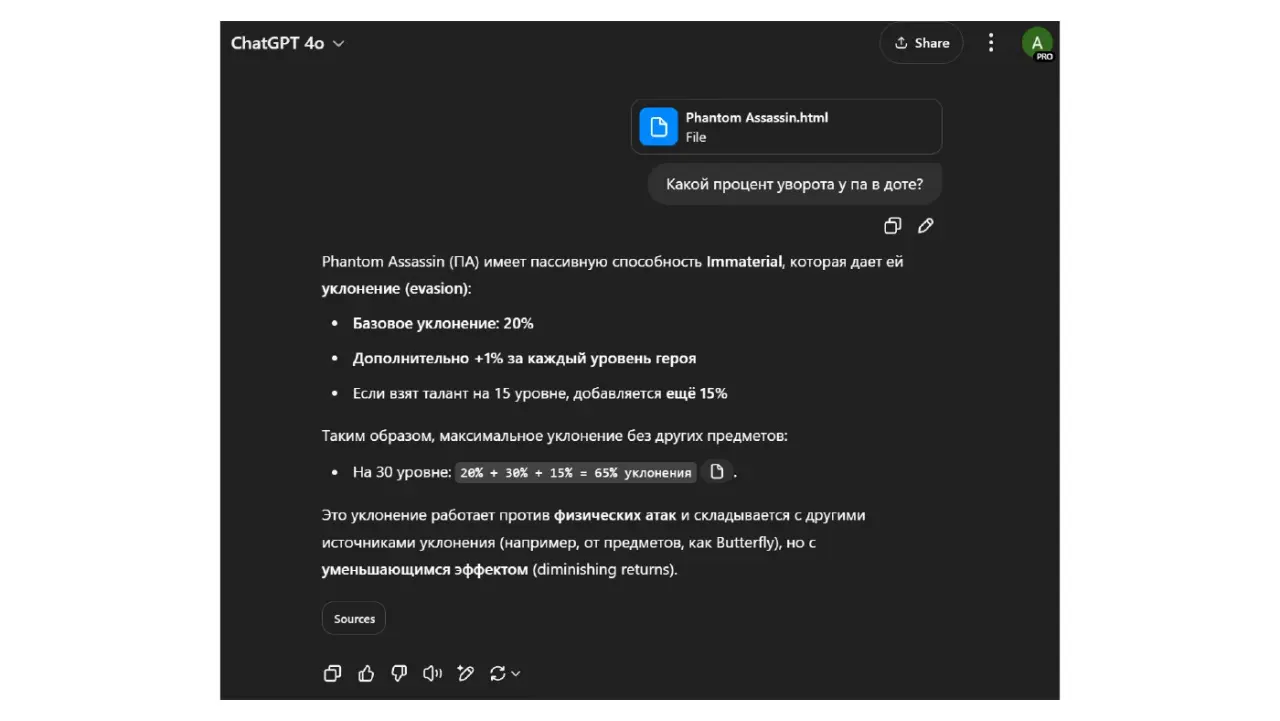
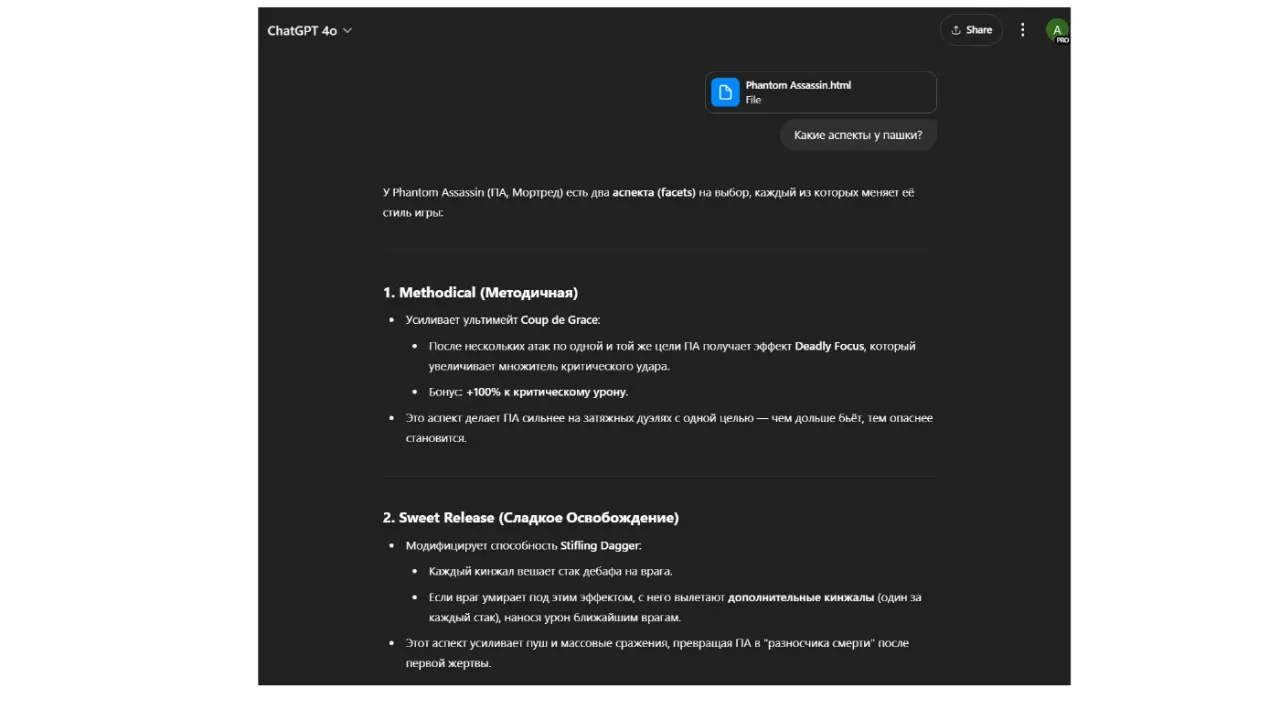
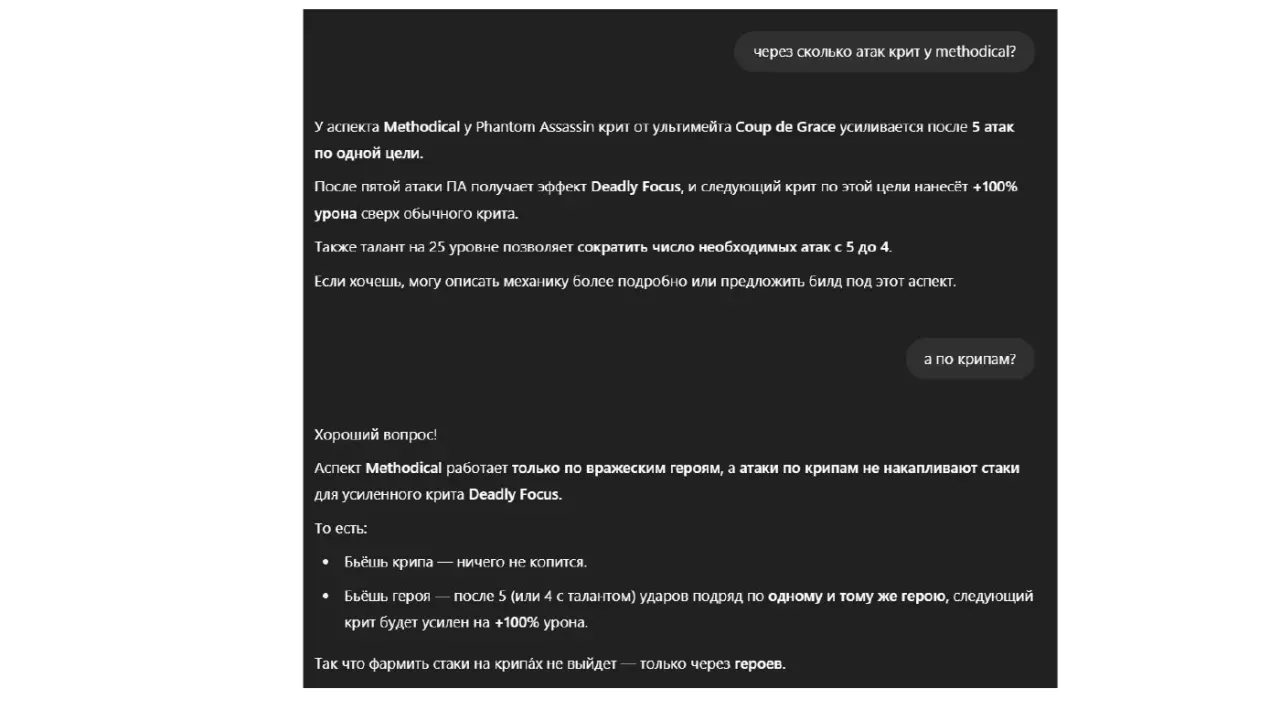
Галлюцинации - LLM врут - Модель оптимизирована на продолжение текста, а не на знание фактов. Если факта нет в ее "вероятностной картине мира", она его додумывает, чтобы ответ звучал складно. Примеры: ● Юмористический: Спросить у LLM рецепт "Бешбармака по-марсиански". Она придумает рецепт, хотя такого не существует. (Легкий, понятный пример выдумки). ● Юмористический: Спросить что-то про доту ● Серьезный: Спросить LLM текущий курс KZT/USD. Она назовет какое-то число, но оно будет выдуманным. Подчеркивает риск неточных данных ● Серьезный: Спросить про законы Казахстана ● Серьезный: Спросить про AirAstana
Слайд 6: LLM ≠ База Данных
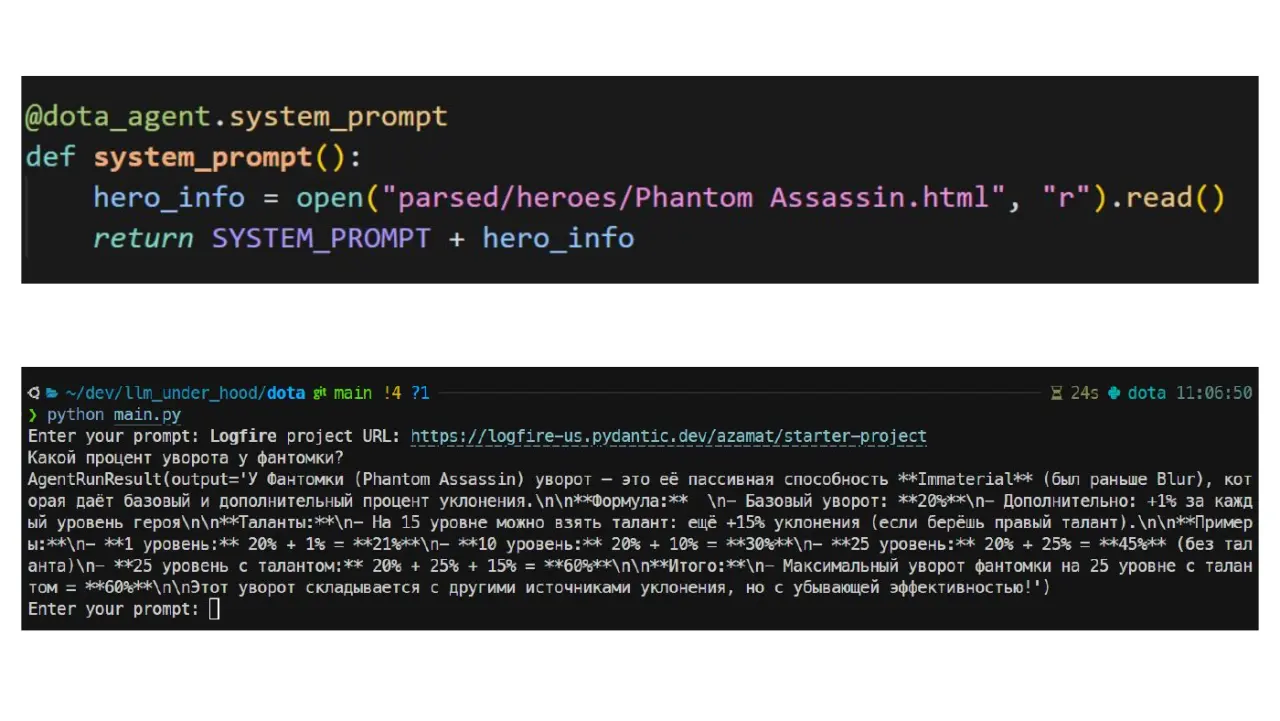
LLM ≠ База Данных - Не думайте об LLM как о всезнающих. Их "знания" - это обобщенная информация из обучающих данных (до Cut-off Date), не актуальная и не специфичная для вашей компании. Это "общее образование", а не эксперт по вашим данным - Концепция: "Не знаешь? Вот тебе шпаргалка, ответь по ней". Подаем релевантный контекст вместе с вопросом Пример - Тот же вопрос про курс KZT/USD. Без контекста - галлюцинация. С актуальной выпиской из нацбанка в промпте - правильный ответ "Иголка в стоге сена": LLM очень хороши в поиске ответа, если он есть в предоставленном контексте (пример с тестом Anthropic про пиццу) Восприятие RAG: Это по сути "умная трансформация промпта" - динамическое добавление нужной информации.
Слайд 7: Мусор на входе = Мусор на выходе
Мусор на входе = Мусор на выходе Проблема 1: Нерелевантный контекст. Если поиск (retrieval) принес не ту информацию, LLM либо проигнорирует ее, либо попытается ответить по ней, что приведет к ошибке. Проблема 2: Противоречивый контекст. Если в контексте несколько противоречащих друг другу фактов (например, из разных версий документа), LLM может запутаться или выбрать неверный. Проблема 3: Слишком много контекста (Шум). Перегрузка контекста большим количеством слаборелевантной информации снижает способность LLM сфокусироваться на нужном ("замыливается глаз"). Пример: Противоречия: Спросить у RAG "Какой email у HR-директора?", а в контекст попали куски из старого и нового регламента с разными email'ами. LLM может выдать старый или оба. Шум: Спросить "Какая процедура отпуска для новых сотрудников?", а ретривер принес 10 страниц общего HR-регламента. LLM может "потерять" нужный абзац
Слайд 8: Пример
Пример Длина контекста. Берем один годовой отчет AirAstana (PDF). Загружаем весь текст в GPT-4o (128k context) Задаем вопрос: "Сколько тонн топлива было израсходовано AirAstana в 2023 году?" -> Модель отвечает правильно (предположим). Теперь говорим: "А если у нас 5 таких отчетов за разные годы? Это уже превысит лимит контекста большинства моделей! Нужна внешняя база." -> Подводим к RAG.
Слайд 11: Пример
Пример
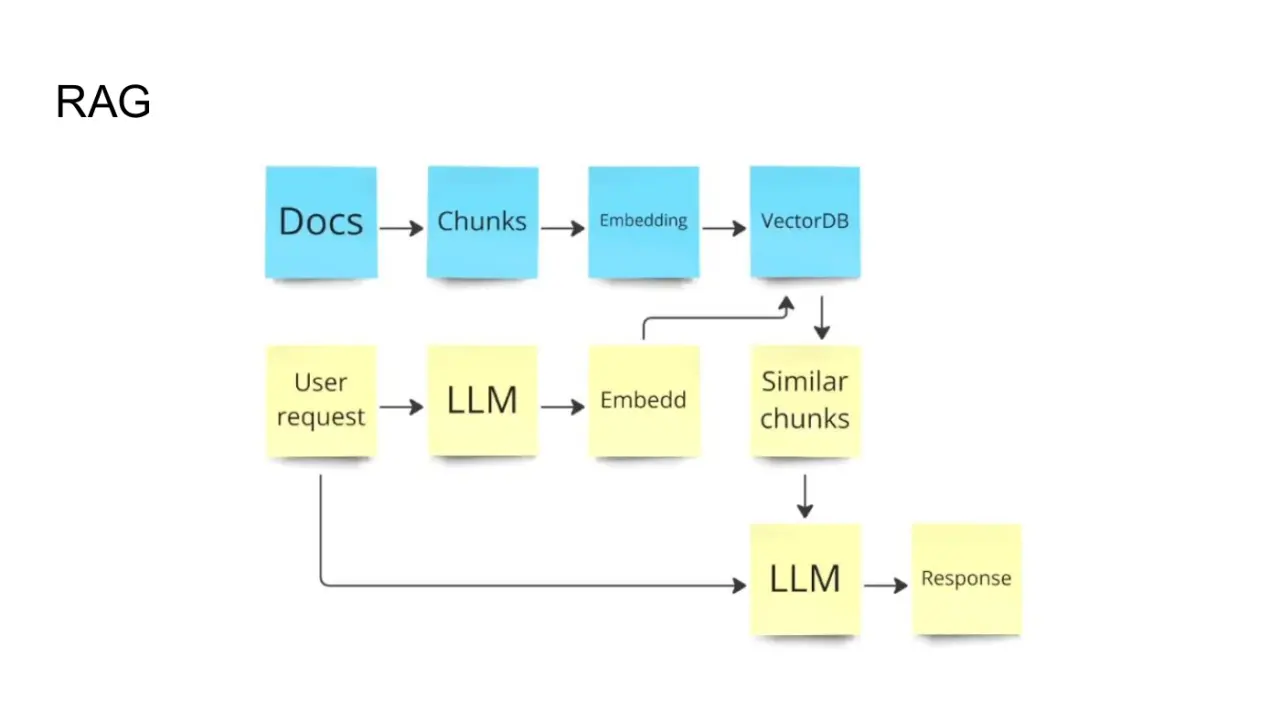
Слайд 24: RAG
RAG
Слайд 25: Дебаг и Подводные Камни
Дебаг и Подводные Камни Смотрим, какие чанки нашел ретривер. Они релевантны? Содержат ли они точный ответ? Или только похожие слова?
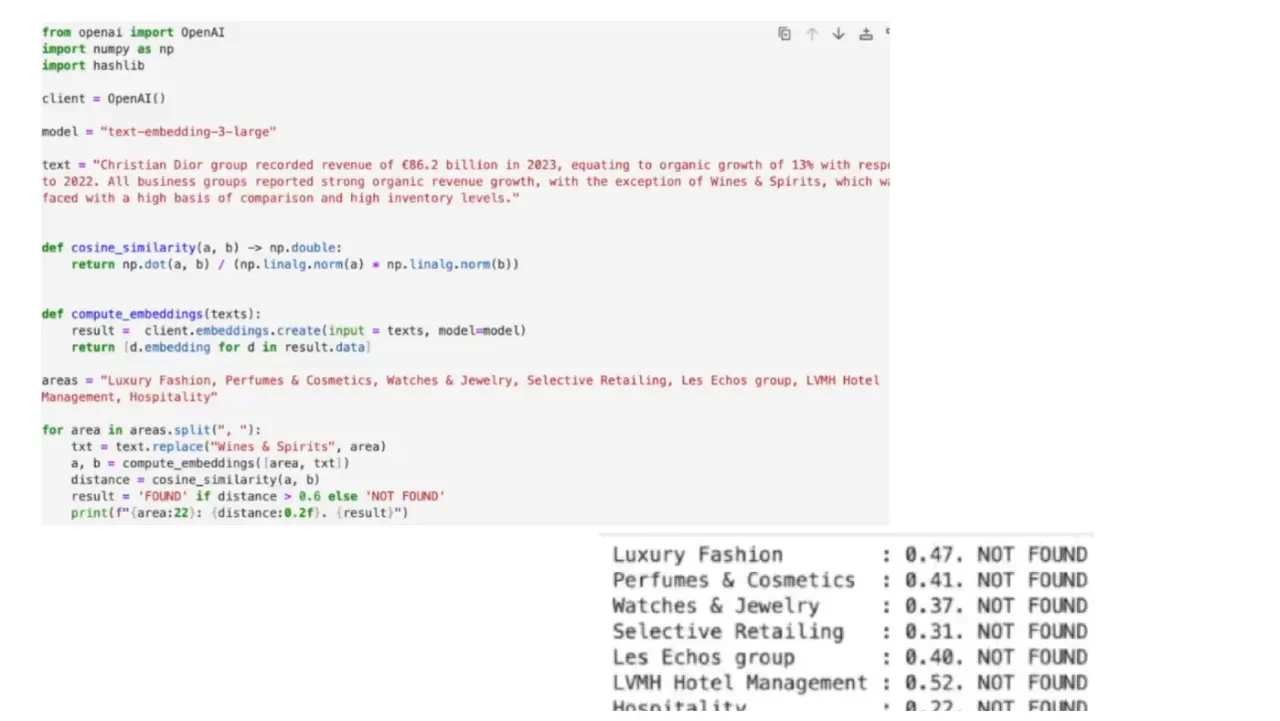
Слайд 26: Вектора - не магия
Вектора - не магия Рассказать как BM25 зачастую оказывается одним из лучших вариантов поиска релевантной информации Гибридный поиск: Комбинация векторного (смысл) и полнотекстового (ключевые слова) поиска
Слайд 28: Паттерны
Паттерны Query Expansion: Переформулирование запроса (LLM или синонимы) для лучшего охвата. Checklists / Workflows: Разбиение сложных запросов на подзадачи Качественный Парсинг: Docling, сериализация таблиц LLM Reranking, Роутинг, CoT+SO
Слайд 29: Тестирование
Тестирование Метрики Retrieval: Нашел ли ретривер чанк(и) с правильным ответом? (Context Recall) Сколько "мусорных" чанков он принес? (Context Precision) Метрики Generation: Если релевантный контекст был найден, сгенерировала ли LLM правильный ответ? (Faithfulness / Answer Accuracy) Unit tests vs e2e (llm judge)
Слайд 30: Итоги
Итоги Понимание корней проблемы галлюцинаций и ограничений RAG. Набор конкретных инженерных паттернов для повышения надежности. Практические подходы к дебагу и оценке LLM-систем. Инженерный mindset: LLM - это не магия, а технология, требующая правильных подходов.
Слайд 31: Вопросы
Вопросы
Другие доклады митапа
- ДСObservability и OpenTelemetry Дмитрий Стародубов
- ТКCursor и AI-ассистент в разработке Темирлан Кабылбеков
- ТИ

